大数据学习笔记5-离线项目学习

十一.一个离线项目
(一).前期
1.目标

2.一些技术了解
数据湖是吞吐大量数据的存储空间。数据湖国外用Apache Hudi
数仓是有目标的
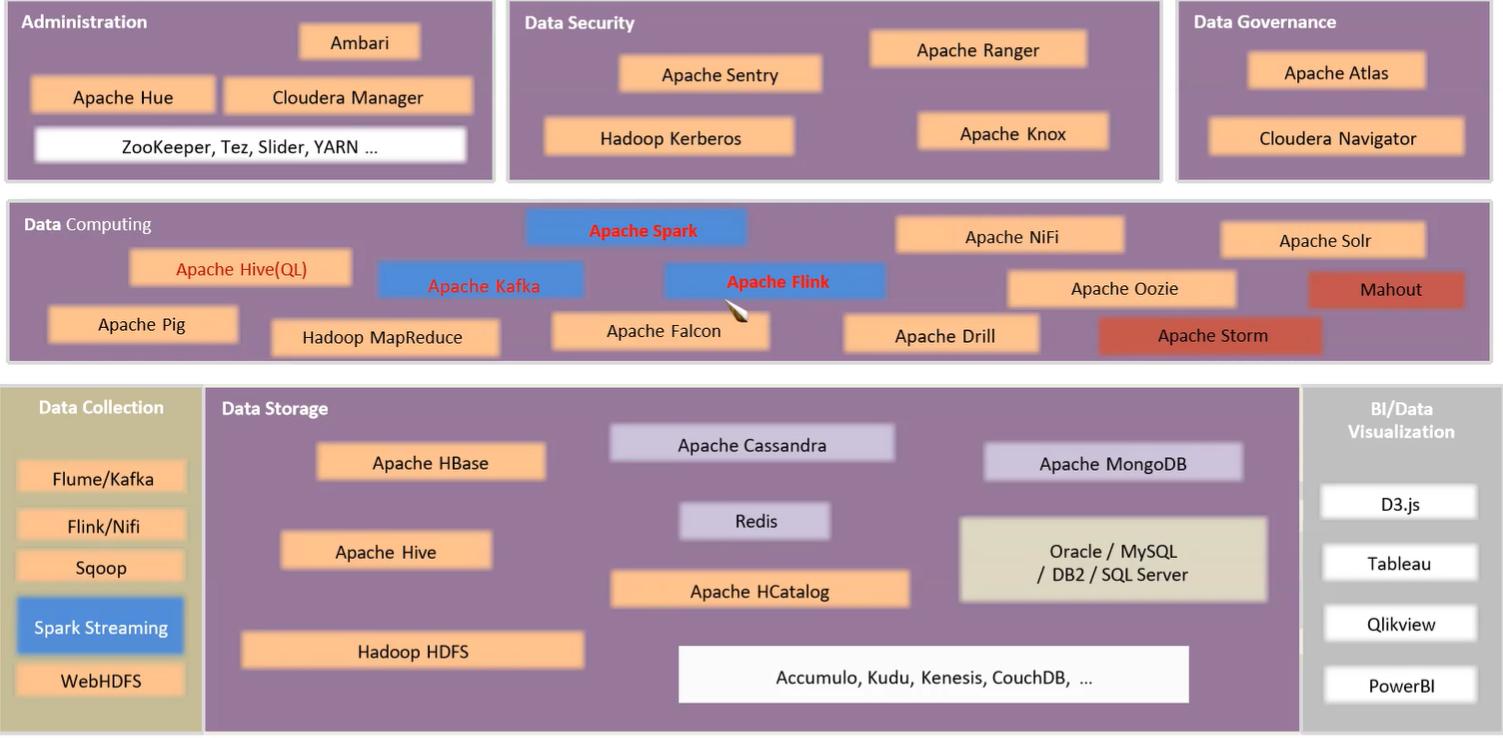
技术栈

Security中关于安全传输的内容。DataGovernance用于元数据管理
中间的Pig太老了,被Hive替代,Storm被Flink替代
阿里clickHouse也是一个Data Storage,可以自学一下。
Administration管理器还有K8S
(二).项目过程
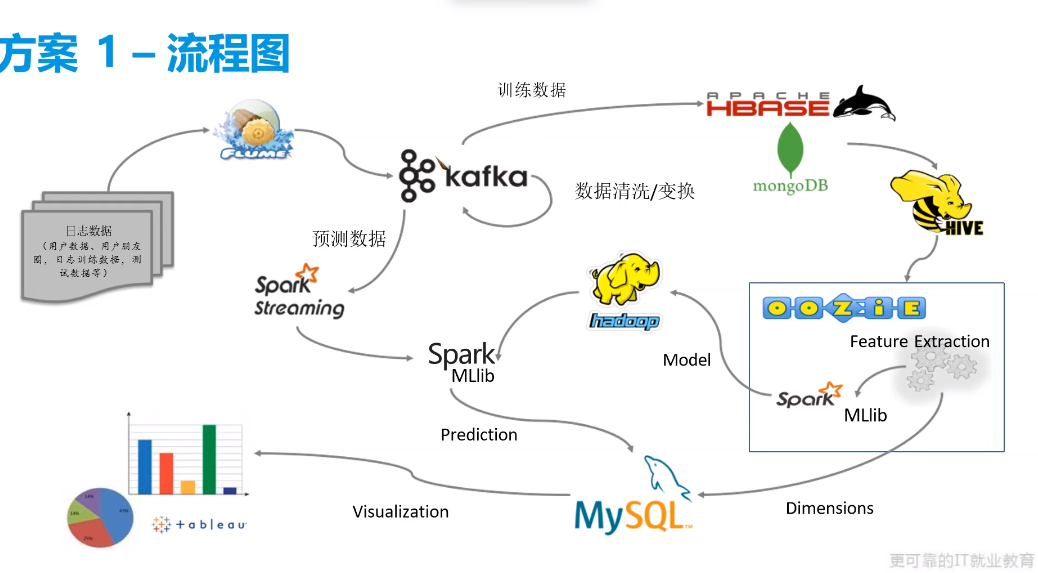
- 这是学习用方案
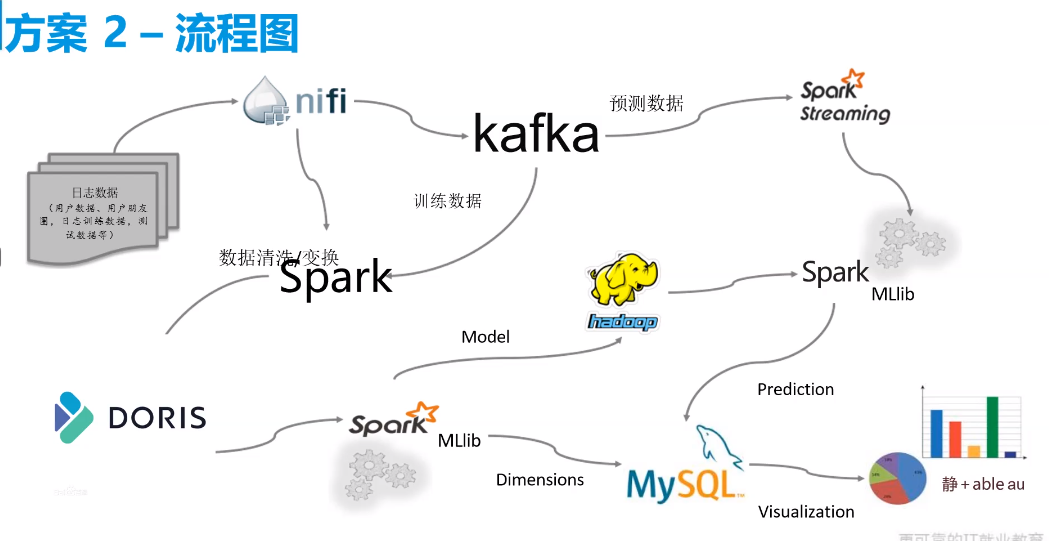
这边用这种方案
- 工作用方案
1.虚拟机配置
本机配置,200G硬盘,20G内存,12核
在分区配置过程,自己分区,点击进入done超链接,删掉/home的位置空间,swap32GiB,/给167GiB,算出来的。建议swap是内存的两倍
i will configure partitioning
配置基础,jdk,mysql,hadoop,hive,zeppelin,hbase,spark
2.Scala数据探索
- 在本地建立quickstart,idea项目名discovery
- 写个trait用于不同表的探索,探索类交叉
- 最后制作成文档用于展示探索结果,以及业务的交涉
3.数据拉取
A.通过Flume传输,但是hdfs没这么高吞吐量中间用个Kafka
Flume->Kafka->
A.Flume传到Kafka
先开启kafka
每个文件要先看行数用于最后判断是否争取,首行是什么作为正则筛选,最长一行字节数作为参数设置
/opt/flumecfg/event_uf.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/data/user_friends
a1.sources.r1.deserializer.maxLineLength = 60000 #该文件最大长度超过50000
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.excludeEvents = true
a1.sources.r1.interceptors.i1.regex= ^user\,friends$ # 正则匹配也会影响效率
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flumeck/eventuf/checkpoint
a1.channels.c1.dataDirs = /opt/flumeck/eventuf/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = orgin_uf
a1.sinks.k1.kafka.bootstrap.servers = 192.168.179.140:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1/opt/flumecfg/event_users.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/data/users
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.excludeEvents = true
a1.sources.r1.interceptors.i1.regex= .*locale\,birthyear\,gender.*
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flumeck/eventuser/checkpoint
a1.channels.c1.dataDirs = /opt/flumeck/eventuser/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = users
a1.sinks.k1.kafka.bootstrap.servers = 192.168.179.140:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1启动消费端监控
1
kafka-console-consumer.sh --bootstrap-server 192.168.179.140:9092 --topic users
运行flume
1
flume-ng agent -n a1 -f /opt/flumecfg/event_users.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console
B.Java转传Kafka
读比较小的数据
甲方不让我们在服务器上下载flume的情况
代码
quickstart,这边工程文件为readfiletoKafka
导包
1
2
3
4
5<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
4.数据从Kafka到Kafka进行简单清理
5.从Kafka到Hbase去重(同时相当于保存在了HDFS中)
6.Hive映射数据
7.离线数仓四层结构
第一第二层哪些数据不能少,即使多了或者少了也要知道原因
对于全是特征的的数据进行聚类分组形成表
第一层ADS映射和放数据
第二层DWD数据清洗
- 创建DWD数据库
- 映射ods层的train表到dwd层
- 清洗用户表—2.1 制作一个临时表将locale所有的变化都进行编号
- 清洗用户表—2.2 制作一个临时表计算用户年份的中位数年份
- 清洗用户表—2.3 制作一个性别生成函数
- 清洗用户表—生成timezone数据对照临时表
- 清洗用户表
- 压缩events表
- 导入eventAttendees表
- 压缩UserFriends表
- 创建eventgroup表
第三层做宽表思考业务相关性的简单指标
做成单独表
思考特征,后期要机器学习
此处思考的特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51train_interested_y ------------- train
train_eventid ------------- train
train_userid ------------- train
train_invited ------------- train
train_ts ------------- train
event_userid ------------- events
event_starttime ------------- events
event_lat ------------- events
event_lng ------------- events
event_group(算) ------------- events+eventgroup
event_month(统) ------------- events
event_hour(统) ------------- events
event_dayofweek(统) ------------- events
event_city_level(统) ------------- events
event_state_level(统) ------------- events
event_country_level(统) ------------- events
users_birthyear_age ------------- users
users_gender ------------- users
users_joinedday ------------- users
users_location ------------- users
users_zone ------------- users
users_localid ------------- users
uf_train_creator_isfriend(统) ------------- train+userfriend+events
event_user_similar(统) ------------- events+train+users
uf_friendcount(统) ------------- userFriends
uf_ea_yes_count(统) ------------- userFriends+train+eventAttendees
uf_ea_no_count(统) ------------- userFriends+train+eventAttendees
uf_ea_maybe_count(统) ------------- userFriends+train+eventAttendees
uf_ea_invited_count(统) ------------- userFriends+train+eventAttendees
uf_ea_yes_count_prec(统) ------------- userFriends+train+eventAttendees
uf_ea_no_count_prec(统) ------------- userFriends+train+eventAttendees
uf_ea_maybe_count_prec(统) ------------- userFriends+train+eventAttendees
uf_ea_invited_count_prec(统) ------------- userFriends+train+eventAttendees
user_ea_yes_count(统) ------------- train+user+eventAttendees
user_ea_no_count(统) ------------- train+user+eventAttendees
user_ea_maybe_count(统) ------------- train+user+eventAttendees
user_ea_invited_count(统) ------------- train+user+eventAttendees
user_ea_count(统) ------------- train+user+eventAttendees
user_ea_yes_count_prec(统) ------------- train+user+eventAttendees
user_ea_maybe_prec(统) ------------- train+user+eventAttendees
user_ea_invited_prec(统) ------------- train+user+eventAttendees
#user_ea_avg_isArrive(统) ------------- died创建dws_interested数据库
创建雪花模型-事实表(train)
将会议表和会议组表结合成1张表 降维
创建雪花模型-维度表(users)
训练集用户是否是会议主持人的朋友
会议和用户是否同城
训练集用户自身参会及反馈统计
训练集用户朋友在本次会议中答复情况的统计
三张表join了以后数据条数10亿以上,内存不够,关掉mapjoin也不行,于是多做中间表,尽量把表变小留下必要数据,join时变少
训练集用户朋友在本次会议中答复情况的统计2
统计每个用户朋友的数量
计算每个城市、省份、国家等级
会议lat lng max_min值
第四层进行合并成宽表
机器学习 机器学习的工程文件夹,spkmodel
8.统计过程中需要对数字很大的列进行归一化
法一
$$
Y=\frac {X-min}{max-min}
$$法二
Z-core归一化
$$
Y=\frac {X-mean}{std}
$$
9.对于宽表用模型计算
- 这边用的分类模型中的随机森林模型
- 将计算好的模型保存
10.test集转化为需要的宽表格式
- 这边用spark做各种清理和数据的传输
- 工程文件名
scalaProject/eventpred - 工程结构:
A.读写
工程中用了三种,1是文件读写,2是Kafka的读取,3是Hive的读取
用了一个特质ReadSource,下面用三个特质来继承,相当于Java中接口和实现,分别为
- FileReadSource
- HiveReadSource
- KafkaReadSource
下面用了一个类ReadDataSource来进行动态混入。Test对象用于引用,做实例化.
这些读取的数据最后放到某个文件夹中,当作仓库,ods层。不需要处理的就直接放到dwd层
当然,如果内存够用,可以四层处理全部放在内存中,不落盘。
ReadSource中只有一个接口
1
def read(param:Map[String,String],spark:SparkSession):DataFrame
用Map传递参数,因为各种类型不一样
各种参数名用一个来存储对象,这边的对象名叫FinalSourceConfig
其中知识点:动态混入,读写spark,有无头,文件、Hive、Kafka读写。Map来传递参数,参数对象。对象来进行枚举。
B.数据清洗
需要的数据直接拉取过来,每一层都用来一个对象来处理,但是实际上一层用一个对象太乱了,最好每一个表的处理都单独出来
没有OPS是因为,前面拉取数据相当于是这步操作了,有些不需要处理的直接放到dwd文件夹中
DWDEvent
DWSEvent
- 文件读写都要用,因此用高级函数放在中间,这是需要改变的部分
- 其中知识点:高级函数,SparkSQL,文件的读写。SparkSQL中的udf函数。udf中有scala的三元表达式。select中一个指定了来自哪个表,其他的也要指定。写如何只写成一个,而不会一行一个文件
- 参数用Map来存储,然后调用对象取静态的枚举值。
ADSEvent
数据取出来的名字和顺序都要和训练的时候一模一样。
List同时给多val赋值
数据存入mysql
11.宽表放入之前训练好的模型中预测
- 宽表的数据也要变成模型需要的数据,要有label
- 预测也在了eventpred的ADSEvent中
- 预测结果保存在Mysql中,也可以放在ClickHouse、Doris等等。同时把维度表也放进去
12.用帆软等工具进行数据展示
- 用帆软访问数据库数据,但是复杂语句特别慢,应该在mysql中建起相应表,帆软只做简单查询
(三).归纳总结
spark中cast()中间变化要Type:
$"birthyear".cast(IntegerType)df.select("locale").rdd.filterrdd出RDD[row]可以吹:
- 数据倾斜,排序的时候空最多,直接去掉空,然后最后加上一个-1个空排序就会在最后,而且减去了大量的数据
(四).其中知识点
1.spark性能调优
语句可以用exits,distinct,collect_list等等来缩
增大内存
1
2
3
4
5
6val spark = SparkSession.builder()
.master("local[*]")
.config("spark.driver.memory","16g")
.config("spark.executor.memory","16g")
.appName("disc")
.getOrCreate()分段计算
十二.Flume架构
Flume用于将多种来源的日志以流的方式传输至Hadoop或者其它目的地
- 一种可靠、可用的高效分布式数据收集服务
Flume拥有基于数据流上的简单灵活架构,支持容错、故障转移与恢复
由Cloudera 2009年捐赠给Apache,现为Apache顶级项目
-
黑体就是一定要填的数据,黄色背景是示例
阿里系:DataX
(一)Flume架构
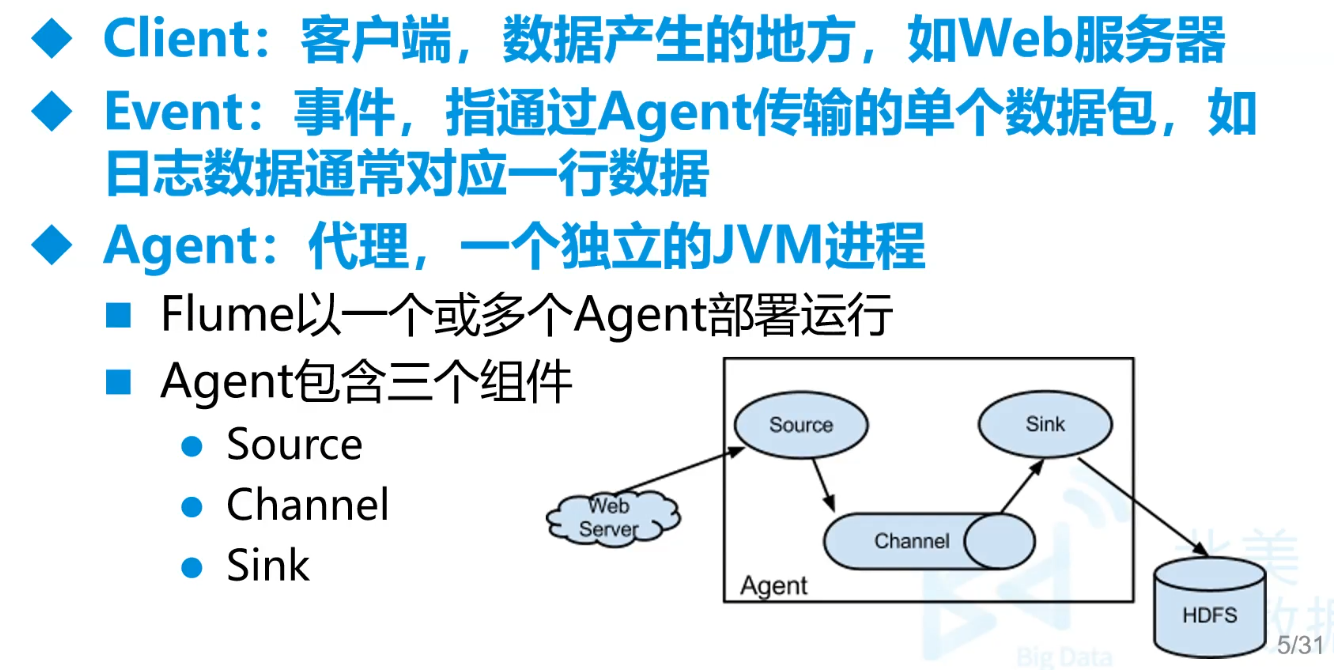
sink是输出,channel是配置载体,source配置来源。还有其他组件,这三个是组成部分
例子
前面的名随意,示例名。
source:
Taildir Source可传输实时的数据
netcat命令终端nc传递的数据
spoolDir是离线传输文件数据
channel:
Memory 内存管道,速度快,但是容易丢
File 类似于检查点,会保存成文件,稳定性高。但是可能多传文件
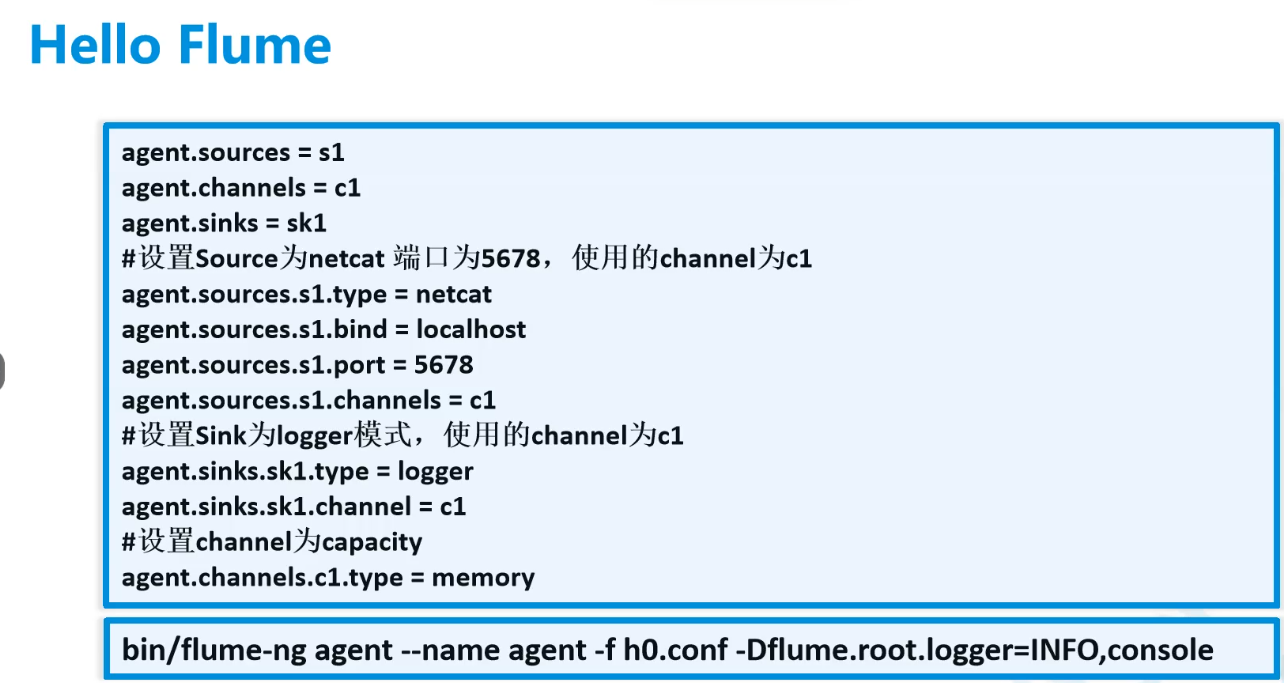
(二).安装
准备好
flume-ng-1.6.0-cdh5.14.2.tar.gzcd /opt tar -zxf flume-ng-1.6.0-cdh5.14.2.tar.gz mv apache-flume-1.6.0-cdh5.14.2-bin/ soft/flume160 cd soft/flume160/conf/ cp flume-env.sh.template flume-env.shvim /etc/profile1
2
3
4
5
6
vim flume-env.sh
```sh
改
export JAVA_HOME=/opt/soft/jdk180source /etc/profile1
2
3#Flume
export FLUME_HOME=/opt/soft/flume160
export PATH=$PATH:$FLUME_HOME/bin
(三)使用
- 使用后读的文件会有个后缀,后缀去掉才能再读
1.第一次使用netcat
1 | cd /opt |
然后到用户指南文档找channel和Source这边是netcat source 和memory
还有很多其他参数
1 | # vim firstnetcat.conf |
先启动这个
1 | flume-ng agent -n a1 -f /opt/flumecfg/firstnetcat.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console |
-n后是实例名称
yum install -y nc,用于测试 nc ip地址 6666先启动这个
然后在nc这边输入,另一边有反应
2.文件读到控制台离线
源:Spooling Directory Source
/opt/flumecfg/secfolder.conf1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/eventdata/train
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.excludeEvents = true
a1.sources.r1.interceptors.i1.regex= ^user.*$ // 正则筛选掉表头
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1读取
1
flume-ng agent -n a1 -f /opt/flumecfg/secfolder.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console
3.文件读到控制台实时
/opt/flumecfg/thirddnyc.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 # 可以多个
a1.sources.r1.filegroups.f1 = /opt/data/train/abc # 监控的文件
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1对于
1
flume-ng agent -n a1 -f /opt/flumecfg/thirddnyc.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console
4.读取没有的源(自定义)
Custom Source
比如数据库
过程(这边是取mysql的数据)
新建maven项目调好
包
1
2
3
4
5<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency>往进程中塞数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98package com.njupt.custflume;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class MySource extends AbstractSource
implements Configurable, PollableSource {
private String url;
private String username;
private String password;
private String tablename;
Connection connection;
ResultSet rs;
PreparedStatement pstat;
/**
* 当source没有数据可以封装时,会让source所在的线程休息一会
* @return
*/
public long getBackOffSleepIncrement(){
return 0;
}
/**
* 当source没有数据可以封装时,会让source所在的线程休息的最大时间
* @return
*/
public long getMaxBackOffSleepInterval(){
return 0;
}
public synchronized void stop() {
// 每次process执行完后执行一次
try {
rs.close();
pstat.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
super.stop();
}
public Status process() throws EventDeliveryException {
//改方法中的会被反复执行
try {
// List<Event> lst = new ArrayList<>();
while (rs.next()) {
String line = rs.getInt("userid")+","
+rs.getString("username")+","
+rs.getString("birthday");
SimpleEvent event = new SimpleEvent();
event.setBody(line.getBytes());
this.getChannelProcessor().processEvent(event); // 会反复调用
// this.getChannelProcessor().processEventBatch(); // 其中传List可以按批传输
}
return Status.READY;
} catch (Exception e){
return Status.BACKOFF;
}
}
public void configure(Context context) {
// 该方法中的内容在一开始执行一次
this.url = context.getString("dburl");
// key,default
this.username=context.getString("dbname","root");
this.password=context.getString("dbpwd","ok");
this.tablename=context.getString("table");
try {
Class.forName("com.mysql.jdbc.Driver");
this.connection = DriverManager.getConnection(url, username, password);
pstat = connection.prepareStatement("select * from " + tablename);
rs = pstat.executeQuery();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}打包放入
/opt/soft/flume160/lib同时要把mysql驱动jar也方进这个文件夹中,这边时mysql5,因此用mysql-connector-java-5.1.38.jar写flume配置
下面配置中的参数名要和java程序中的对应好
/opt/flumecfg/fourcust.conf1
2
3
4
5
6
7
8
9
10
11
12
13a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = com.njupt.custflume.MySource
a1.sources.r1.dburl = jdbc:mysql://192.168.179.140:3306/mydemo
a1.sources.r1.table = userinfos
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1执行
1
flume-ng agent -n a1 -f /opt/flumecfg/fourcust.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console
5.文件通过文件读到logger
/opt/flumecfg/fivefile.conf1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/data/events
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.excludeEvents = true
a1.sources.r1.interceptors.i1.regex= .*event_id.*
a1.sinks.k1.type = logger
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flumeck/checkpoint
a1.channels.c1.dataDirs = /opt/flumeck/data
6.文件通过文件读到hdfs
但实际上hdfs读写速度慢,撑不住Flume大量的写入,因此需要中间件Kafka
1 | a1.channels = c1 |
十三.Kafka###重要
(一)前期
- 是消息队列
- 为了处理数据洪峰
- 吞吐量最厉害的软件之一
- 上述的flume速度远大于HDFS,flume导入数据用Kafka作为中间件
- 需要内存,相当于一个漏斗,一个通道,临时存放数据
- Apache
- 存到Kafka中的内容默认只能存在7天
- 后续传输的位置大概率是Hbase、Redis一类东西。并解决自动提交去重方式
1.消息中间件(MQ)
- 异步调用
同步变异步 - 应用解耦
提供基于数据的接口层 - 流量削峰
缓解瞬时高流量压力
2.消息中间件中的术语
- Broker:消息服务器,提供核心服务
- Producer:消息生产者
- Consumer:消息消费者
- Topic:主题,发布订阅模式下的消息统一汇集地,一个消息可以开好多队列来存储(分区)
- Queue:队列,P2P模式下的消息队列
3.消息中间件工作模式
- p2p和广播
4.常见中间件
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
- Redis
- ……
- Redis更便宜,在相对数量不大时,用Redis,大了用Kafka
5.Apache Kafka
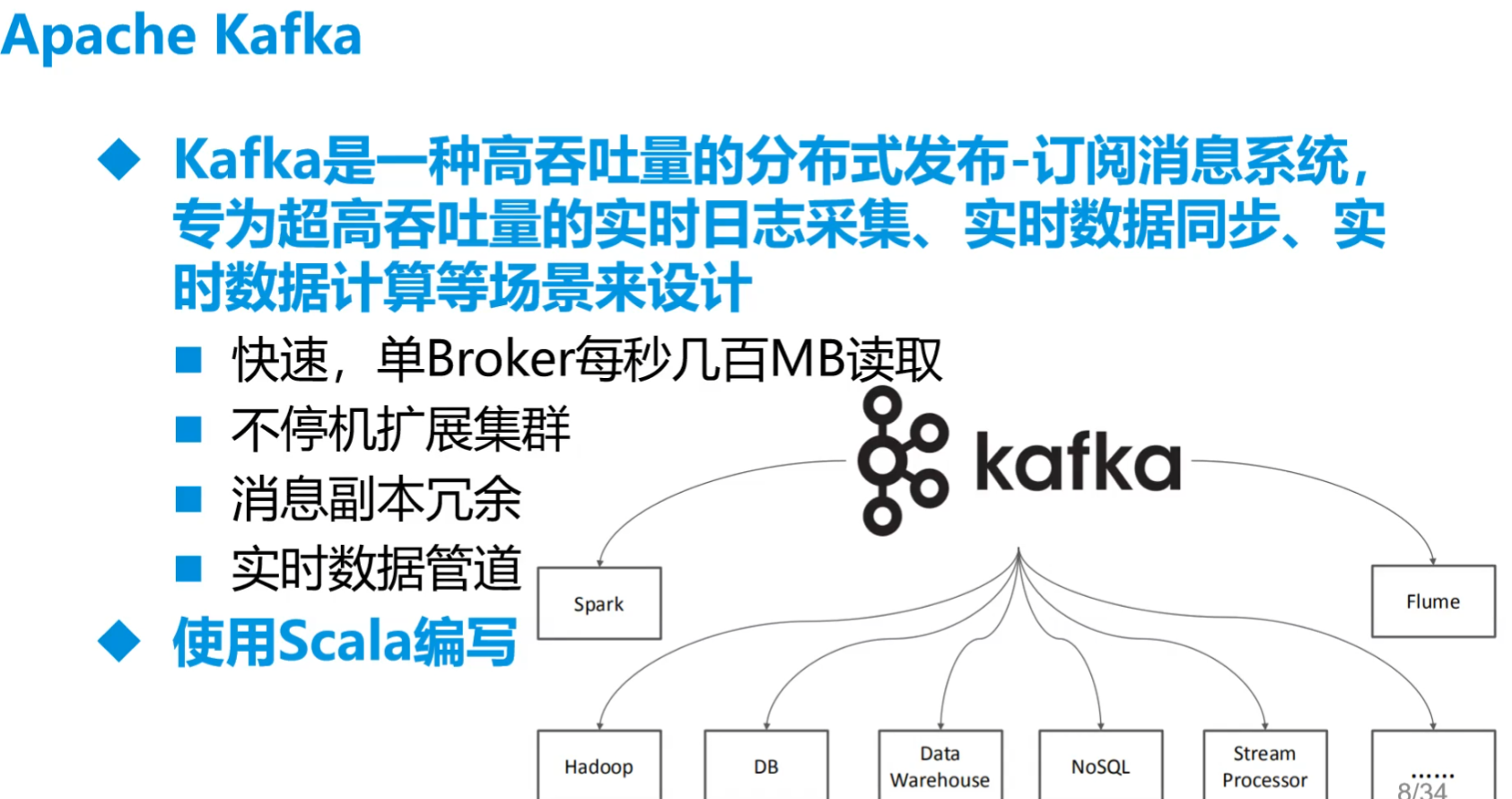
(二)安装
要装好了zookeeper,准备好
kafka_2.11-2.0.0.tgz放opt中cd /opt tar -zxf kafka_2.11-2.0.0.tgz mv kafka_2.11-2.0.0 soft/kafka200 cd soft/kafka200/config/1
2
3
4
5
6
7
8
9
10```
3. vim server.properties
- 这个中broker.id是集群的编号
- log.retention.bytes:数据保留时间
```properties
listeners=PLAINTEXT://192.168.179.140:9092
log.dirs=/opt/soft/kafka200/logs #日志位置
zookeeper.connect=localhost:2181 # 要自己的vim /etc/profile
1
2
3#Kafka
export KAFKA_HOME=/opt/soft/kafka200
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
(三)使用
1.第一次使用
zookeeper要先启动
终端上启动kafka
1
2kafka-server-start.sh /opt/soft/kafka200/config/server.properties
nohup kafka-server-start.sh /opt/soft/kafka200/config/server.properties > /root/kafka.log 2>&1 &查看是否有消息队列
1
kafka-topics.sh --zookeeper 192.168.179.140:2181 --list
创建消息队列
kafka-topics.sh --zookeeper 192.168.179.140:2181 --create --topic mydemo --replication-factor 1 --partitions 11
2
3
4
5kafka-topics.sh --create \
--zookeeper 你的zookeeper的IP:2181 \
--replication-factor 副本数 \
--partitions 分区数 \
--topic 消息队列名查看队列里是否有数据
1
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 192.168.179.140:9092 --topic mydemo --time -1
结果:mydemo:0:0。
消息队列名:消息队列中第几个队列:这个消息队列有几条消息-1是用时间戳代表最新的偏移量
控制台生产端下达命令
1
kafka-console-producer.sh --topic mydemo --broker-list 192.168.179.140:9092
然后可以输入数据
消费端开启
1
kafka-console-consumer.sh --bootstrap-server 192.168.179.140:9092 --topic mydemo
生产端输入数据
输入完后消费端出现数据,进入logs文件夹会出现很多很多游标和消息队列
zkCli.sh可以查看zookeeper中内容
手工删除消息队列,要在logs中删除,再到zookeeper /brokers/topics中删掉
命令删除消息队列,要在
server.properties加入Delete.topic.enable=true然后命令
1
kafka-topics.sh --delete --zookeeper 192.168.179.140:2181 --topic mydemo
删除过程会十分缓慢
初始化指针位置
1
kafka-consumer-groups.sh --bootstrap-server 192.168.179.140:9092 --group cm --reset-offsets --to-earliest --topic mydemo --execute
查看组
1
kafka-consumer-groups.sh --bootstrap-server <kafka-broker>:9092 --list
查看数据
1
kafka-console-consumer.sh --bootstrap-server hadoopproject:9092 --topic carpass --from-beginning
2.三个分区
kafka-topics.sh --create --zookeeper 192.168.179.140:2181 --topic mydemo --replication-factor 1 --partitions 3会看到
kafka-console-consumer.sh --bootstrap-server 192.168.179.140:9092 --topic mydemo1
2
3mydemo:0:0
mydemo:1:0
mydemo:2:0输入数据
1
kafka-console-producer.sh --topic mydemo --broker-list 192.168.179.140:9092
kafka-console-consumer.sh --bootstrap-server 192.168.179.140:9092 --topic mydemo查看,会发现放入数据是轮询的方式Kafka顺序和效率的互斥性
- 分区无法保证输入输出数据的顺序
- 但能加快吞吐数据。
- 因此要顺序就开单分区
3.Flume数据输入Kafka(数据丢失与重复问题)
Flume参数
生产端ack应答机制:
0不等待回应
1等待leader接收到消息
-1 等待所有副本确认。速度很慢,但能保证数据不丢。
ISR(In-Sync Replicas)机制要保证leader和所有副本中数据一致。
leader接收到数据先不落盘,先写日志。再通知follow节点,这些节点全部落盘后,leader才会落盘
Kafka中本身要-1才会干活,单Flume可以在这三种情况下继续传数据
-1就是ISR机制
生产端安全性,丢数据的问题,用ack应答机制-1等到所有副本应答后再传输。
幂等性
重复性问题:传数据,断电。没收到ack,再传一样的,后来连续两次收到一样的。
生产者无论想broker发送多少次重复的数据,broker都只持久化一条
方法:再kafka配置文件中开启enable.idempotence。默认为true,false关闭
只能保证单会话单分区内不重复,内存内直接会把重复的数据去掉。开启事务必须开启幂等性。
数据丢失
- 生产端数据丢失 使用ack应答机制-1
- 消费端数据丢失 由于自动提交偏移量,可以用手动
数据重复
- 生产端数据重复 开启幂等性
- 消费端数据重复 手动提交偏移量时,可以通过Hbase、redis等去重(对于允许去重的)。对于本身的重复不能舍去时,可以对Hbase的行键进行一定的组合
Flume配置文件内容
/opt/flumecfg/event_users.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/data/users
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_filter
a1.sources.r1.interceptors.i1.excludeEvents = true
a1.sources.r1.interceptors.i1.regex= .*locale\,birthyear\,gender.*
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/flumeck/eventuser/checkpoint
a1.channels.c1.dataDirs = /opt/flumeck/eventuser/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = users
a1.sinks.k1.kafka.bootstrap.servers = 192.168.179.140:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1启动消费端监控
1
kafka-console-consumer.sh --bootstrap-server 192.168.179.140:9092 --topic users
运行flume
1
flume-ng -n a1 -f /opt/flumecfg/event_users.conf -c /opt/soft/flume160/conf/ -Dflume.root.logger=INFO,console
(四)学习
1.ZooKeeper再Kafka中的作用
zookeeper中内容会和Kafka紧密关联

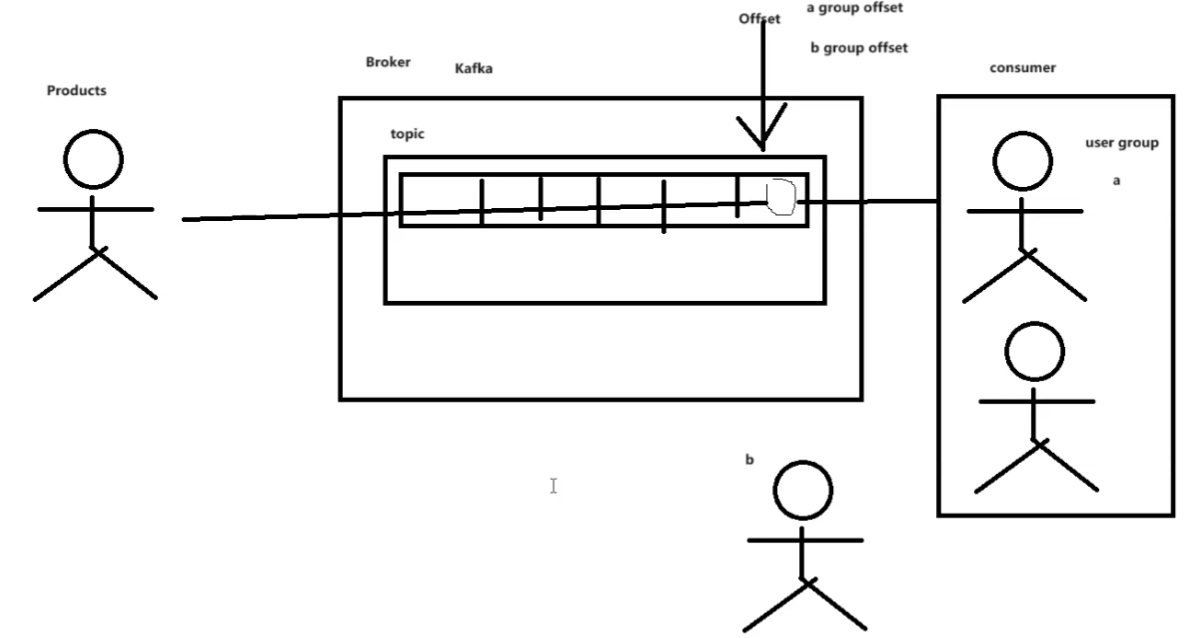
(五)核心原理
单对单
内部有队列,同一组(group)的只有一根游标offset
一次读完后想再读有两个选择:
- 换个组
- 通过命令将offset置位
多台broker构成集群,这些中要有一台leader和多台follow
(六)API应用
1.Java转传Kafka(生产者)
读比较小的数据
甲方不让我们在服务器上下载flume的情况
图片中的配置有点老了,可以看代码中的新的
KafkaProducer中K,V,K相当于可以指定分区,同样K的会被分到同一个分区,V是一行数据
代码
quickstart,这边工程文件为readfiletoKafka
导包
1
2
3
4
5<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76public class RRWKafkaUtilsImpl implements RWKafkaUtils {
private Properties prop;
private Map<String,String> topics;
public RRWKafkaUtilsImpl(Properties properties, Map<String, String> tps) {
this.prop = properties;
this.topics = tps;
}
public void writeKafka(Map<String, List<String>> data) {
// 开启线程池
ExecutorService pool = Executors.newFixedThreadPool(data.size());
for (String key : data.keySet()) {
final List<String> ctx = data.get(key);
final String topic =topics.get(key);
pool.execute(()->{
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
for (String line : ctx) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic,line);
producer.send(record);
}
producer.close();
});
}
pool.shutdown();
}
}
package com.njupt.readfiletokafka.commons;
import com.njupt.readfiletokafka.commons.handimpl.StringDataHandlerImp;
import com.njupt.readfiletokafka.commons.kafkaimpl.RRWKafkaUtilsImpl;
import com.njupt.readfiletokafka.commons.readimpl.ReadCSVFileUtil;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
public class MyTest {
static ReadFileUtils rcfu = new ReadCSVFileUtil();
static DataHandler dh = new StringDataHandlerImp();
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.179.140:9092");
prop.put(ProducerConfig.ACKS_CONFIG, "all");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
Map<String,String> topics = new HashMap<>();
topics.put("train.csv","train");
topics.put("test.csv","test");
topics.put("time_zone.csv","timezone");
try {
Map<String, List<String>> mp = rcfu.read("E:\\ProgramFile\\BigDataStudy\\data\\scalaProject\\temp");
HashMap<String, Boolean> header = new HashMap<>();
header.put("train.csv",true);
header.put("test.csv",true);
header.put("time_zone.csv",false);
Map<String,List<String>> newMp = dh.handler(mp, header);
RWKafkaUtils rw = new RRWKafkaUtilsImpl(prop,topics);
rw.writeKafka(newMp);
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面这个代码中是一行一行塞入的,效率显然有点低,找找一批一批的方式。
好像找不到

2.Kafka读出(消费者)
- 消费者的读过程是一个死循环

参数”enable.auto.commit”是设置是否自动提交。
自动提交会导致重复数据,手动提交重复数据后接Hbase或者Redis去重
poll里面的时间要算好,吞吐量要符合要求。现在用Deration填充值,是多长时间给一次数据。
这边的类是反序列化
rprop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); // 开启手动提交- 获取的值要用value()来展示 - 如果使用Spark要在读出for循环上面加个1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
- 一个组共用一个offset,到最后就不能读了,因此只能读一次。
有两个方法继续读:
1. 新开一组
参数`ConsumerConfig.GROUP_ID_CONFIG`改组
2. 将偏移量归0
命令行下命令
`kafka-consumer-groups.sh --bootstrap-server 192.168.179.140:9092 --group cm --reset-offsets --to-earliest --topic mydemo --execute`
将某组的某个topic的offset设置为0,只能在该组没人使用的时候才能执行
- 演示代码
- 包和前面一致
- 代码
```Java
public class ReadKafkaImpl implements ReadKafka {
Properties prop;
public ReadKafkaImpl(Properties properties){
this.prop = properties;
}
@Override
public void read(String topic) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> re = consumer.poll(Duration.ofSeconds(5)); // 当没有数据过来时,轮询的时间
// System.out.println(System.currentTimeMillis()+"======"+ re.count());
for (ConsumerRecord<String, String> record : re) {
System.out.println(record.value());
}
}
}
}
public class MyTest {
// 从kafka读出去
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.179.140:9092");
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "cm");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"1000"); // 配置一批出去多少数据,默认四五百
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
ReadKafkaImpl rki = new ReadKafkaImpl(prop);
rki.read("events");
}
}1
import scala.collection.JavaConversions._
3.Kafka到kafka(手动提交)
用于处理数据
这边的读过程就是消费者过程用手动提交——offset偏移自己来,不会少数据,但可能会重复消费:消费者挂掉了!此时offset还未提交呢,那么当服务重启时,还是会拉取相同的一批数据重复处理!造成消息重复消费。因此后续最好接上一个幂等性的数据库来去重。比如Hbase,但Hbase速度比Kafka慢,而且行键要进行盐+hash
同步提交
1
consumer.commitSync();
同步率低,速度慢,因为会等
异步提交
1
consumer.commitAsync();
重复率高,速度快
A.Java
包
1
2
3
4
5<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59public class KafkaDataHandlerUtils {
Properties readProp;
Properties writeProp;
private String readTopic;
private String writeTopic;
public KafkaDataHandlerUtils(Properties readProp, Properties writeProp, String readTopic, String writeTopic) {
this.readProp = readProp;
this.writeProp = writeProp;
this.readTopic = readTopic;
this.writeTopic = writeTopic;
}
public void rwHandler(DataHandler dh) {
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(readProp);
consumer.subscribe(Arrays.asList(readTopic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1200)); // 1.2S轮询时间
KafkaProducer<String,String> producer = new KafkaProducer<>(writeProp);
for (ConsumerRecord<String, String> record : records) {
List<String> datas = dh.handler(record.value());
for (String line : datas) {
ProducerRecord<String, String> pr = new ProducerRecord<>(writeTopic, line);
producer.send(pr);
}
consumer.commitSync(); // 同步提交,手动提交
}
producer.close();
}
}
}
public class MyMain {
public static void main(String[] args) {
Properties wprop = new Properties();
wprop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.179.140:9092");
wprop.put(ProducerConfig.ACKS_CONFIG, "all");
wprop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
wprop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
Properties rprop = new Properties();
rprop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.179.140:9092");
rprop.put(ConsumerConfig.GROUP_ID_CONFIG, "cm001");
rprop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
rprop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
rprop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"400"); // 107513B*400大概50M左右,虚拟机设置的速度有限制LSI logic最高传输速度为按机械硬盘算
rprop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
rprop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); // 开启手动提交
String rtopic = "orgin_ea";
String wtopic = "eventAttendees";
KafkaDataHandlerUtils ku = new KafkaDataHandlerUtils(rprop, wprop, rtopic, wtopic);
ku.rwHandler(new EventAttendeesDataHandler());
}
}
4.Kafka读到Hbase
public class EventsImpl implements HbaseDataHandler { @Override public Put change(String line) { String[] infos = line.split(",",-1); Put put = new Put(infos[0].getBytes()); // 用hashcode会让效率更高,分布更均匀,但是在大量的数据下可能会导致出的hash值相同 put.addColumn("base".getBytes(), "eventid".getBytes(), infos[0].getBytes()); put.addColumn("base".getBytes(), "userid".getBytes(), infos[1].getBytes()); put.addColumn("base".getBytes(), "starttime".getBytes(), infos[2].getBytes()); put.addColumn("base".getBytes(), "city".getBytes(), infos[3].getBytes()); put.addColumn("base".getBytes(), "state".getBytes(), infos[4].getBytes()); put.addColumn("base".getBytes(), "zip".getBytes(), infos[5].getBytes()); put.addColumn("base".getBytes(), "country".getBytes(), infos[6].getBytes()); put.addColumn("base".getBytes(), "lat".getBytes(), infos[7].getBytes()); put.addColumn("base".getBytes(), "lng".getBytes(), infos[8].getBytes()); for (int i = 1; i <= 101; i++) { put.addColumn("base".getBytes(), ("c" + i).getBytes(), infos[i + 8].getBytes()); } return put; } } public class KafkaToHabase { private Properties readProp; private String topic; private String zookeeperAddr; private String hbaseTableName; public KafkaToHabase(Properties readProp, String topic, String zookeeperAddr, String hbaseTableName) { this.readProp = readProp; this.topic = topic; this.zookeeperAddr = zookeeperAddr; this.hbaseTableName = hbaseTableName; } public void dataTranscation(HbaseDataHandler hdh) throws Exception{ KafkaConsumer<String, String> consumer = new KafkaConsumer<>(readProp); consumer.subscribe(Arrays.asList(topic)); Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum",zookeeperAddr); Connection connection = ConnectionFactory.createConnection(conf); BufferedMutatorParams bmp = new BufferedMutatorParams(TableName.valueOf(hbaseTableName)); bmp.writeBufferSize(5 * 1024 * 1024); bmp.setWriteBufferPeriodicFlushTimerTickMs(2000); final BufferedMutator bm = connection.getBufferedMutator(bmp); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); List<Put> puts = new ArrayList<>(); for(ConsumerRecord<String,String> record:records){ Put put = hdh.change(record.value()); puts.add(put); } System.out.println("========="+puts.size()); bm.mutate(puts); bm.flush(); puts.clear(); consumer.commitSync(); } } } public class NewMain { public static void main(String[] args) throws Exception{ Properties prop = new Properties(); prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.179.140:9092"); prop.put(ConsumerConfig.GROUP_ID_CONFIG, "cm011"); prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"2600"); prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); // 开启手动提交 String topic = "events"; String zkAddr = "192.168.179.140:2181"; String hbaseTable = "interested:events"; KafkaToHabase kth = new KafkaToHabase(prop, topic, zkAddr, hbaseTable); kth.dataTranscation(new EventsImpl()); } }可以先把`prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"2600");`量拉大,看最大能多少,然后发现吞吐量大小。然后2600/1算出值大概比前面最大的来小一点。大一点会更快,但是会导致1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
## (七)进阶学习
### 1.#重要#判断kafka输出的对象的接收速度
- 通过
```java
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"2600"); // Kafka每一次拉取数据的大小
bmp.writeBufferSize(5 * 1024 * 1024); //hbase buffer中超过这个量传一次数据5M
bmp.setWriteBufferPeriodicFlushTimerTickMs(2000); //hbase buffer中每2秒再传一次数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // Kafka每1秒拉取一次数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
这里的“1秒”(1000毫秒)并不是指消费者每1秒读取一次数据,而是指`poll`方法在没有新数据到达的情况下等待的时间。换句话说,如果在这1秒内没有新的消息到达,`poll`方法会返回一个空的结果,然后你的代码可能会再次调用`poll`方法,继续等待新的消息。
如果在这1秒内确实有新的消息到达,`poll`方法会立即返回这些消息,而不需要等待完整的1秒。因此,消费者的读取频率取决于消息到达的频率,而不是固定的每1秒读取一次。
当数据都在Kafka中的时候,这个1秒可以看作读取数据的时间间隔
# 十四.Spark Streaming
- 流的特点是有头无尾
## (一)开始
### 1.常见流处理框架
- Apache Spark Streaming
- Apache Flink
- Confluent
- Apache Storm
### 2.Spark Streaming简介
- 我们这儿用的Spark是2.3.4
- 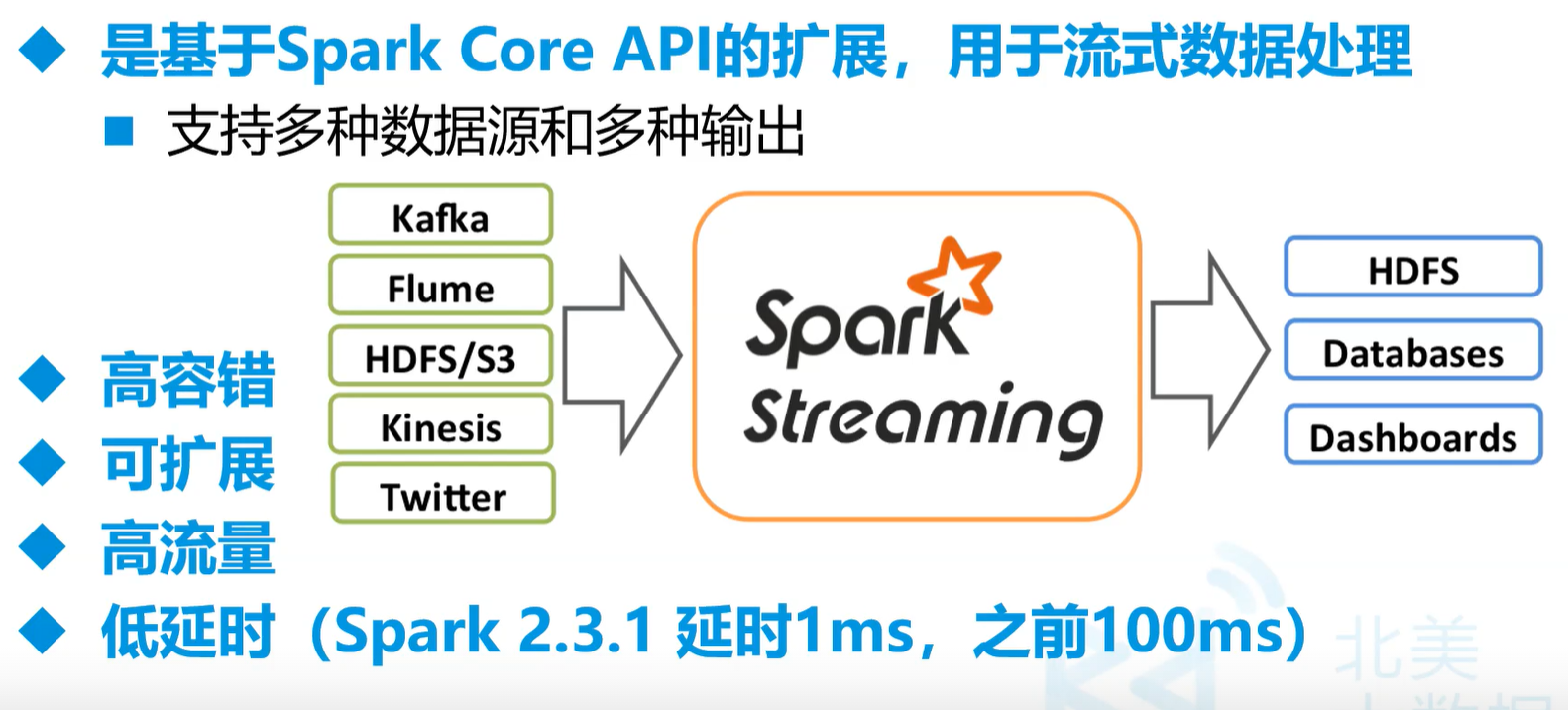
dashboards是面板,相当于是那些软件
- 真的实时流要来一条处理一条,不能设置时间
- Spark Streaming相当于**微批处理**,是**伪实时流**。最小可以1ms为窗口,一般情况下是10ms
### 3.Spark Streaming 流数据处理架构
- 典型架构
- 流式数仓
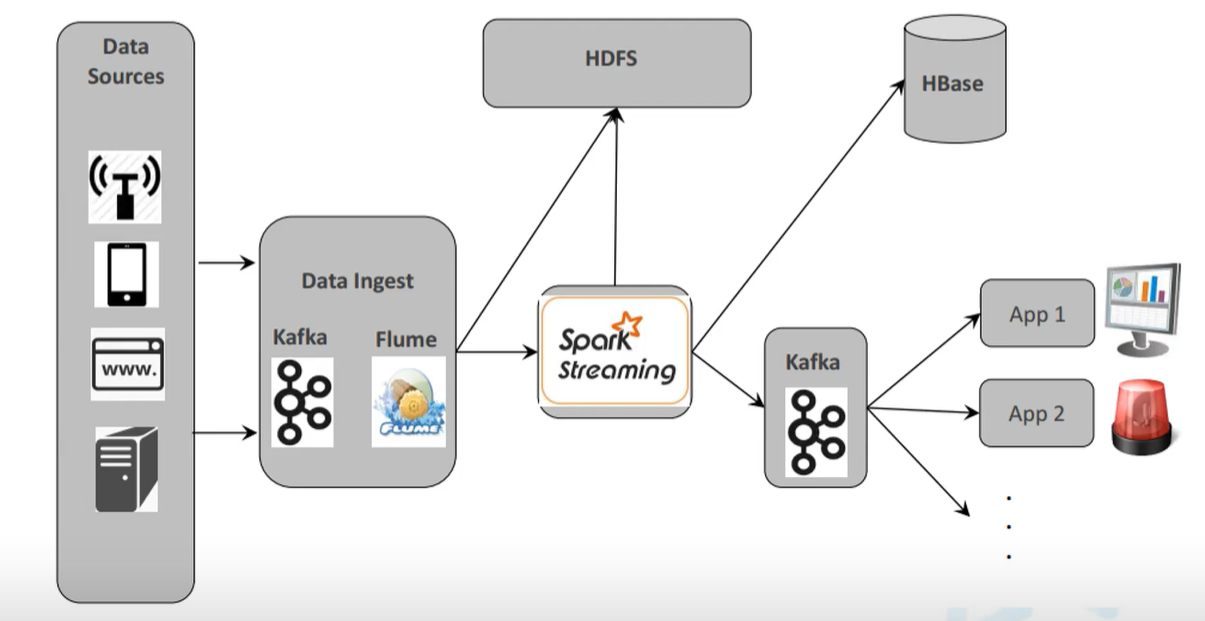
- 实时数仓为了追求效率,一般层数很少。而且层数基本是按硬件来分的,中间的Kafka和Flume那相当于是
### 4.Spark Streaming 内部工作流程
- 微批处理:输入->分批处理->结果集
- 以离散流的形式传入数据(DStream:Discretized Streams)
- 流被分成微批次(1-10s),每一个微批都是一个RDD

### 5.内建流式数据源

### 6.DStream支持的转换算子
- <img src="https://pic1.sabthever.cn/Blog_Base_Resouces/bigdata/image-20240804225332570.png" alt="image-20240804225332570" style="zoom: 33%;" />
- updateStateByKey
## (二)使用

### 1.流处理输出数据
- 终端上`nc -lk 19999`打开端口监控,手动输入数据
- 在java这儿每五秒展示一次终端上输入的数据
```scala
object MyStream {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("mystream")
val ssc = new StreamingContext(conf, Seconds(5))
val ds = ssc.socketTextStream("192.168.179.140", 19999)
ds.print()
// ds.foreachRDD(rdd=>println(rdd))
ssc.start();
ssc.awaitTermination();
}
}
导入的包
1 | <dependency> |
- 停止程序会报错,但是没事,因为流有头无尾,是非正常状态的退出
2.Spark Streaming读Kafka
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23object MyStream {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("mystream")
val ssc = new StreamingContext(conf, Seconds(5))
/* val ds = ssc.socketTextStream("192.168.179.140", 19999)
ds.print()
ds.foreachRDD(rdd=>println(rdd))*/
val param = Map[String, String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG-> "192.168.179.140:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "cmm",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer].getName,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer].getName)
var topics = Array("events").toList
var ds=KafkaUtils.createDirectStream[String,String](
ssc,LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](topics,param)
).map(_.value()).print()
ssc.start();
ssc.awaitTermination();
}
}
最后
- 标题: 大数据学习笔记5-离线项目学习
- 作者: Sabthever
- 创建于 : 2025-09-11 10:28:34
- 更新于 : 2025-10-09 16:14:31
- 链接: https://sabthever.cn/2025/09/11/technology/bigdata/Hadoop5-离线项目/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
