大数据学习笔记4-Spark

Hadoop4
十.Spark
这边用2.3.4
(一)前期
- MapReduce速度慢,因此用Spark速度比MapRduce快100倍,实际上10倍差不多
- 计算引擎,不启动Hadoop也能干活
- 分布式计算引擎
- 离线数据分析
1.使用原因
- MapReduce编程模型的局限性
- 繁杂
- 只有Map和Reduce两个操作,复杂的逻辑需要大量的样板代码
- 处理效率低:、
- Map中间结果写磁盘,Reduce写HDFS,多个Map通过HDFS交换数据
- 任务调度与启动开销大
- 不适合迭代处理、交互式处理和流式处理
- 繁杂
- Spark是类Hadoop MapReduce的通用并行框架
- Job中间输出结果可以保存在内存,不再需要读写HDFS,优先占内存
- 比MapReduce平均快10倍以上
2.Spark简介
- 加州大学伯克利分校AMP实验室,基于内存的分布式计算框架
- 发展
- 2014.5正式Spark 1.0
- 2016 1.6、2.x版本
3.Spark优势

- spark streaming伪实时流,不怎么用
- 三种提交方式
- 本地提交
- YARN提交:中间还有两种
4.Spark技术栈

(二)内容介绍
1.Spark运行架构
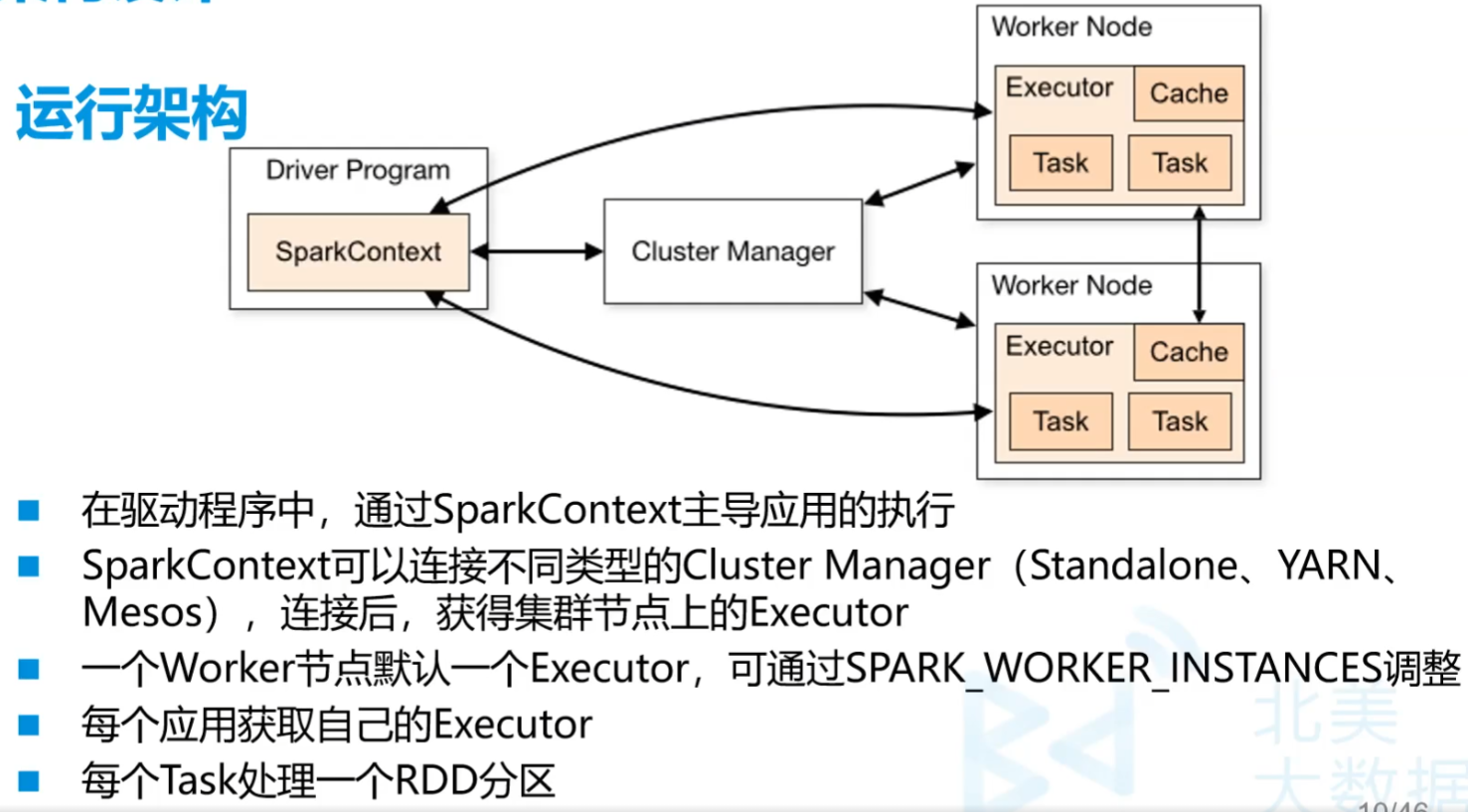
在Spark的Driver节点中,主要运行我们提交的程序,程序的入口就是SparkContext。Driver节点会加载Spark的执行环境SparkEnv, 统计Spark执行过程信息,向Cluster Manager 申请Task需要的资源节点等。Driver在执行提交的程序时,会根据Action算子提交Job。 一个Action算子提交一个Job,并将其交给DAGScheduler, DAGScheduler在submitJob时会从后向前根据血缘关系遍历,如果一个RDD是ShuffleRDD, 会将其前后分为两个Stage。之后,会将TaskSets提交给TaskScheduler, 并封装为TaskManager。最后在Worker节点上启动Executor进程,并将Task分发给Worker节点执行。
程序的提交执行,为一个Application, 其会通过Driver节点向Cluster Manager申请资源,然后在Worker节点启动一批Executor。每一个Executor是一个进程,其只服务于当前申请的Application。一个Worker节点上会存在多个Application申请的Executor进程,它们之间资源是相互隔离的。当分区Task(执行逻辑)分发到当前Worker的Executor上,则会在其上启动一个线程进行执行Task任务。Executor中包含一个blockManager,由于迭代计算会产生很多中间结果,可以将其存储在这个模块中,减少io操作,提高性能。
client端不一定和Driver在一起
Driver是将来运行提交代码的那台服务器
SparkContext作为核心,一个集群里只有一个,是程序的入口
每台机器每个节点相当于Worker Node。一个节点默认一个Executor
Executor是自动开辟的空间,有核有内存
Task的数量由分配给Executor的内核数量决定。是众算子分出来的一个个小任务
算子交付给每一个Executor,方法分配到Task上执行,算子给有数据的机器
MapReduce在Shuffle阶段是Reduce把Mapper拉取过来,影响效率。因此就把算子复制传到节点上并赋予编号,减少数据的传输。通过Yarn来交付,是把程序发过去。过程尽量放内存不落盘。
每一个算子都是一个Task,甚至多个Task。一个Executor可以处理一段算子
Cache是节点间用来传输少量的数据
通过repartition改分区数量。一个Task对应一个RDD分区。假设三台服务器,每台服务器2核。那么repartition(6)就会占用各两个核,超过的话会等某个结束计算后,再让它计算。
2.Spark架构核心组件

Spark一般部署再Hadoop服务器上,方便找Yarn,也方便找数据。Master最好不要放在集群上,防止崩溃
如一个map算子可能会在多节点查数据,所以可能会出现多个Task
一个Job代表一串算子
一个Job分成多组Task,称为Stage。即从一串转换算子到一个行动算子就是一个Stage
一个分区要占用一个核
网上解释
- Job:
- 一个Job是由Spark应用程序中的一个行动(Action)触发的。行动是那些返回数据并触发计算的操作,如
count()、collect()、save()等。 - 一个Job可以包含一个或多个Stage。
- 一个Job是由Spark应用程序中的一个行动(Action)触发的。行动是那些返回数据并触发计算的操作,如
- Stage:
- Stage是Job的一个阶段,代表了一组可以并行执行的任务集合。
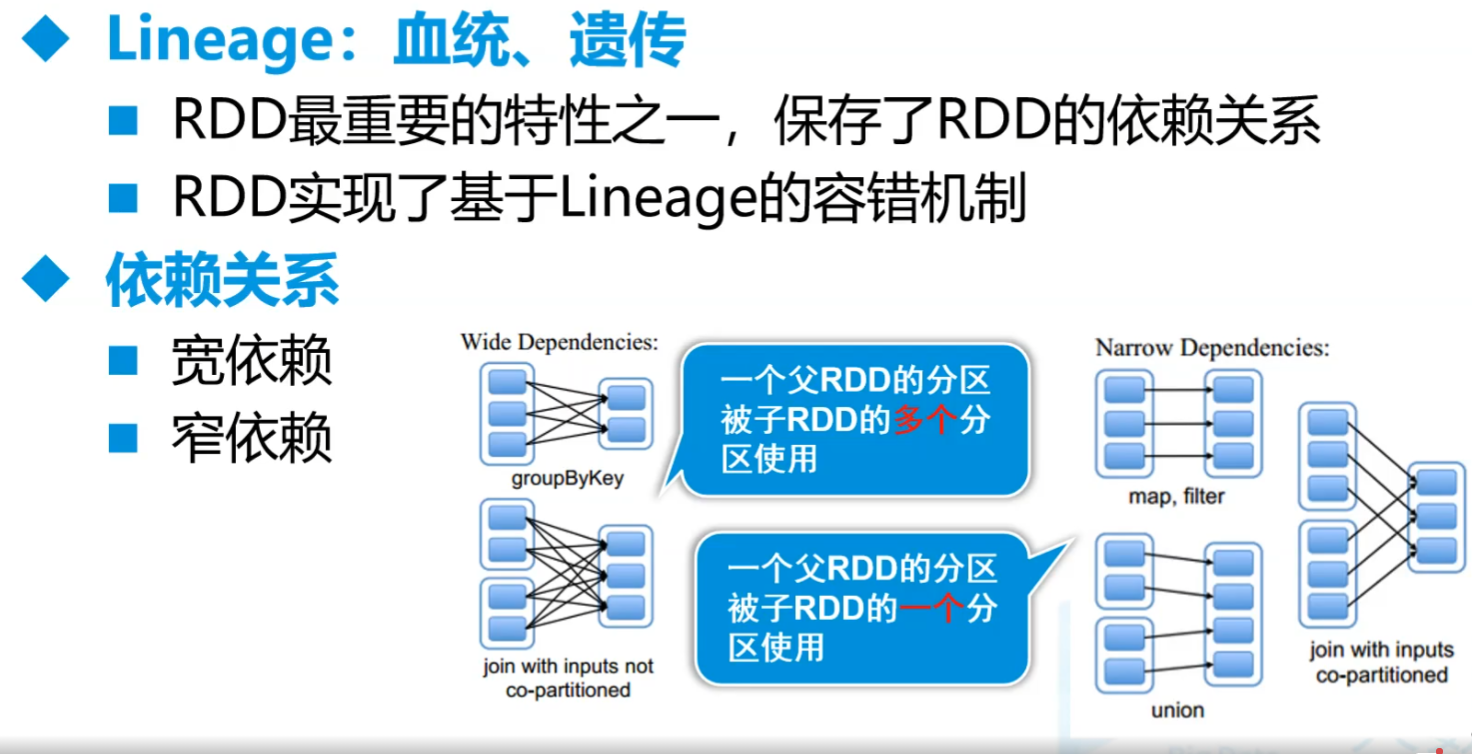
- Stage之间存在依赖关系,通常分为两类:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。
- 窄依赖意味着子RDD的每个分区只依赖于父RDD的一个或少数几个分区,不需要进行数据的shuffle操作。
- 宽依赖则意味着子RDD的每个分区可能依赖于父RDD的所有分区,需要进行数据的shuffle操作。
- 一个Job从逻辑上被划分为多个Stage,每个Stage的结束标志着一个依赖的完成。
- 需要传数据了就是一个阶段
- Task:
- Task是Stage中的基本执行单元,每个Task负责处理数据的一个分区。
- Stage中的所有Task都是并行执行的,每个Task对应RDD的一个分区。
- Task的执行是实际的计算工作,它们读取数据、执行转换操作,并产生结果。
这三个概念之间的关系可以用以下方式描述:
- 当Spark应用程序执行一个行动操作时,它首先触发一个Job。
- Spark的DAG(Directed Acyclic Graph,有向无环图)调度器会根据RDD之间的依赖关系将Job分解为一个或多个Stage。
- 每个Stage进一步被分解为多个Task,这些Task在集群中的不同节点上并行执行。
- 窄依赖:在窄依赖的情况下,子RDD的每个分区只依赖于父RDD的一个或少数几个分区。这种情况下,一个Task确实对应处理一个分区的数据。
- 宽依赖:在宽依赖的情况下,子RDD的每个分区可能依赖于父RDD的所有分区,需要进行数据的shuffle操作。在这种情况下,一个Task可能需要处理来自多个分区的数据。
- 父RDD中的一个Task就是一个分区
- Job:
3.Spark API
- RDD
- Spark核心,主要数据抽象
- 类似数组
- 弹性分布式数据集
- 存储的是算子,相当于高级方法
- Dataset
- 从Spark1.6开始引入的新的抽象,特定领域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作
- 类似对象数组
- DataFrame
- DataFrame是特殊的Dataset
- 结构化的RDD
- 长的像表
4.RDD
A.解释
- 简单的解释
- RDD是将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存和磁盘中,并执行正确的操作
- 复杂的解释
- RDD是用于数据转换的接口
- RDD指向了存储在HDFS、Cassandra、HBase等、或缓存(内存、内存+磁盘、仅磁盘等),或在故障或缓存收回时重新计算其他RDD分区中的数据
- RDD中是没有数据的,里面只有算子和指引对象(数据地址),是分区集合
- 是spark核心
B.完整解释(重要)
- RDD是弹性分布式数据集(Resilient Distributed Datasets)
- 分布式数据集
- RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上
- RDD并不存储真正的数据,只是对数据和操作的描述
- 弹性
- RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘
- 容错性
- 根据数据血统(设置检查点ckeckpoint),可以自动从节点失败中恢复分区
- 分布式数据集
C.DAG
- 有向无环图,算子是不能成环的
D.特性
- 一系列的**分区(分片)**信息,每个任务处理一个分区
- 每个分区上都有compute函数,计算该分区中的数据
- RDD之间有一系列的依赖
- 分区器决定数据(key-value)分配至哪个分区
- 优先位置列表,将计算任务分派到其所在处理数据块的存储位置
E.RDD的使用
a.使用集合创建

parallelize是用于变成RDD的
makeRDD
1 | object MyPartition { |
查看实际的分区
mapPartitionsWithIndex
1 | object MyPartition { |
自己来进行分区,分区一定要用键值对,要重写分区的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22object MyPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("part").setMaster("local[*]")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7),4)
.map(x=>(x,x))
.partitionBy(new MyPart(4))
.mapPartitionsWithIndex((x,iter)=>{
val str=iter.toIterator.toList.mkString(",")
List(s"分区号:${x},分区数据:${str}").toIterator
}).foreach(println);
sc.stop()
}
}
class MyPart(n:Int) extends Partitioner{
override def numPartitions: Int = n
override def getPartition(key: Any): Int = {
val keyNum = key.toString.toInt
keyNum%numPartitions
}
}
b.通过加载文件产生RDD

c.RDD操作(重要)

转换算子一开始都不干活,直到遇到一个行动算子
简而言之,如果你在Spark程序中看到一个操作返回一个新的RDD,那么它很可能是一个转换算子。如果一个操作返回一个值(如整数、列表等),那么它很可能是一个行动算子。
转换算子
mapfiltermapValues原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素,仅适用于PairRDD
-
makeRDDcachepersist
动作算子
countcollect但是这个collect不是scala那个。是以Array形式返回RDD所有数据,十分危险,要消耗大量内存。
collect可以从RDD变为Arraytaketake后的是Array不是RDD,可再用
parallelize转为RDD就可以继续了,也可以用makeRDDreduceforeachlookup用于PairRDD,返回K对应的所有V值
最值saveAsTextFile单反是save都是行动算子,RDD有。落盘文件数量按分区来。如果放在一个文件中,那么就用makeRDD(arr,1)或者使用repartition来设置一个分区
1
2
3
4
5
6
7
8
9val rdd = sc.textFile("E:\\ProgramFile\\BigDataStudy\\data\\customers.csv")
val arr = rdd.map(line => {
val infos = line.split(",")
// (infos(2),infos(1))
(infos(1), infos(2))
}).groupByKey().mapValues(_.toList.size)
.repartition(1).sortBy(-_._2).take(10)
sc.makeRDD(arr,1).saveAsTextFile("e:/Temp/ttt")


F.RDD持久化
缓存
cache和persist是减少重复计算
姓名全部排序输出,用cache()把转换算子的结果放入
cache()来提高效率,重复用的变量尽量都要cache().也得碰到行动算子才会运行

1 | object Exp01 { |
但是内存很有可能没这么打,用
persist,自动cache内存不够自动落盘persist中写缓存策略
MEMORY_ONLY只放内存DISK_ONLY只存硬盘MEMORY_AND_DISK先内存再硬盘MEMORY_AND_DISK_SER序列化存储,提高效率MEMORY_AND_DISK_2内存和落盘都有两个副本(吃内存,不推荐)
改为
1
2
3
4val arr = rdd.map(line => {
val infos = line.split(",")
(infos(1), infos(2))
}).persist(StorageLevel.MEMORY_ONLY)
检查点
检查点 使用来保存相关配置,用于崩溃重启读取处理。一般放在大型计算之前做检查点
改为 不管血统,只保留结果数据。碰到行动算子才会干活
1
2
3
4
5
6
7
8
9
10// 设置检查点目录
sc.setCheckpointDir("e:/Temp/ckpt") // 检查点文件
val rdd = sc.textFile("E:\\ProgramFile\\BigDataStudy\\data\\customers.csv")
val arr = rdd.map(line => {
val infos = line.split(",")
(infos(1), infos(2))
})
arr.checkpoint() // 做个检查点
arr

G.RDD共享变量
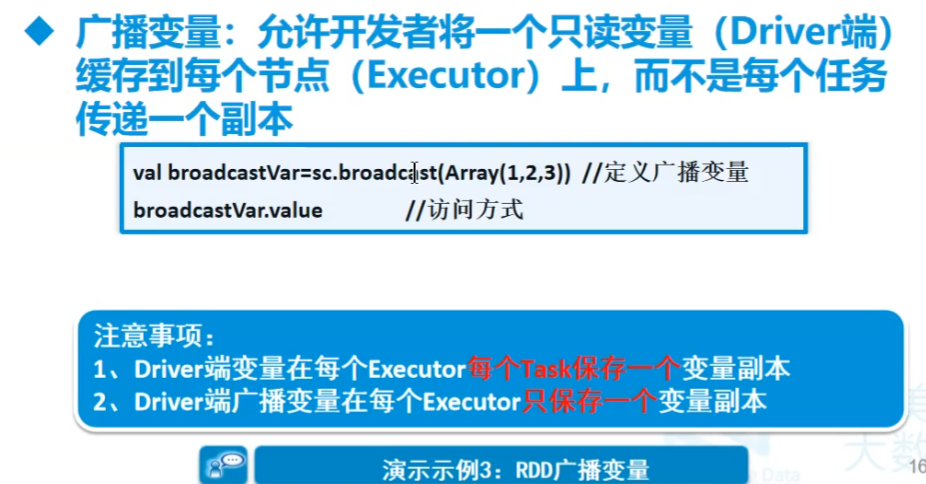
广播变量
广播变量:允许开发者将一个只读变量(Driver端)缓存到每个节点(Executor)上,而不是每个任务传递一个副本
只能针对于能够序列化的对象
广播变量,只读不改
设备温度监控
普通
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30object TemperatureWatch {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("tw")
val sc = SparkContext.getOrCreate(conf)
// 读阈值文件 某台节点上
val threshold = sc.textFile("e:/Temp/thread.txt").cache()
// 读设备温度监控数据 某几个节点上
val macdata = sc.textFile("e:/Temp/mactemp.csv").cache()
// 将阈值文件转为Map(机器部位编号,(最低温度,最高温度))
val thresholdMap:Map[String,(Int,Int)] = threshold.map(line => {
val infos = line.split(",")
(infos(0), (infos(1).toInt, infos(2).toInt))
}).collect().toMap
// 根据设备监控数据和阈值文件将超过阈值的数据过滤出来
macdata.map(line=>{
val infos = line.split(",")
// 根据阈值Map找到机器对应部位的最高最低温度
val (minTemp,maxTemp):(Int,Int)=thresholdMap.get(infos(0)).get
if(infos(1).toInt<minTemp || infos(1).toInt>maxTemp) {
(infos(0),infos(1).toInt,infos(2),"温度异常")
}else{
(infos(0),infos(1).toInt,infos(2),"温度正常")
}
}).foreach(println)
sc.stop()
}
}我们会发现阈值文件特别小,就要放进内存,但是本来就是放到内存中的。但是,Spark是把算子交给有数据的节点,读进内存只是当前的节点。而执行
val (minTemp,maxTemp):(Int,Int)=thresholdMap.get(infos(0)).get这条语句的时候要拉取该节点内存数据,大文件节点拉小文件没问题,但要是是小文件拉大文件,资源消耗太大,要让小文件存到大文件所在的节点中。因此用2的方法广播变量方式
共享变量,把小的数据发送到每一个要用的节点中。这句加在取值后
读取的时候一定要先用
.value读出来1
2// 将阈值Map存放到共享变量中
val tm = sc.broadcast(thresholdMap)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20val thresholdMap:Map[String,(Int,Int)] = threshold.map(line => {
val infos = line.split(",")
(infos(0), (infos(1).toInt, infos(2).toInt))
}).collect().toMap
// 将阈值Map存放到共享变量中
val tm = sc.broadcast(thresholdMap) // ------------
// 根据设备监控数据和阈值文件将超过阈值的数据过滤出来
macdata.map(line=>{
val infos = line.split(",")
// 通过共享变量获取map
val tmap = tm.value // ------------------
// 根据阈值Map找到机器对应部位的最高最低温度
val (minTemp,maxTemp):(Int,Int)=tmap.get(infos(0)).get // ---------
if(infos(1).toInt<minTemp || infos(1).toInt>maxTemp) {
(infos(0),infos(1).toInt,infos(2),"温度异常")
}else{
(infos(0),infos(1).toInt,infos(2),"温度正常")
}
}).foreach(println)
累加器
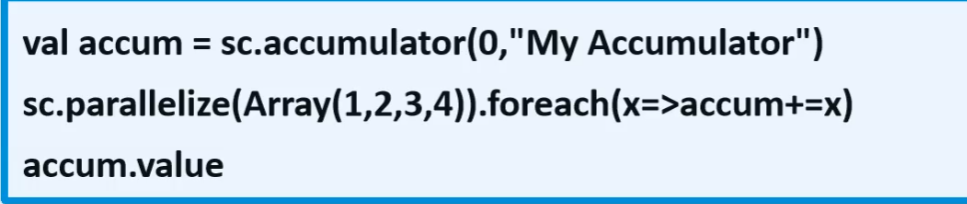
只允许added操作,常用于实现计数
类似于一种原子的操作
例子
1
2
3
4
5
6
7
8
9
10
11
12
13val conf = new SparkConf().setAppName("part").setMaster("local[*]")
val sc = SparkContext.getOrCreate(conf)
// var cnt=0
var cnt=sc.accumulator(0,"cnt")
sc.makeRDD(List(1,2,3,4,5,6,7,8,9,10)).foreach(n=>cnt+=n)
println(cnt.value)
sc.stop()
// 输出55,用ctn=0的方式就不行,出0。因为RDD的操作是在服务器上的
//现在都这么用
val res = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).reduce(_ + _)
println(res)
H.RDD分区设计
- 分区大小限制为2GB
- 分区太少
- 不利于并发
- 更容易受数据倾斜影响
- groupBy,reduceByKey,sortByKey等内存压力增大
- 分区过多
- Shuffle开销越大
- 创建任务开销越大
- 经验
- 每个分区大约128MB
- 如果分区小于但接近2000,则设置为大于2000
5.Spark WordCount运行原理
- 一旦出现shuffle就分stage(阶段),往往是有By操作时
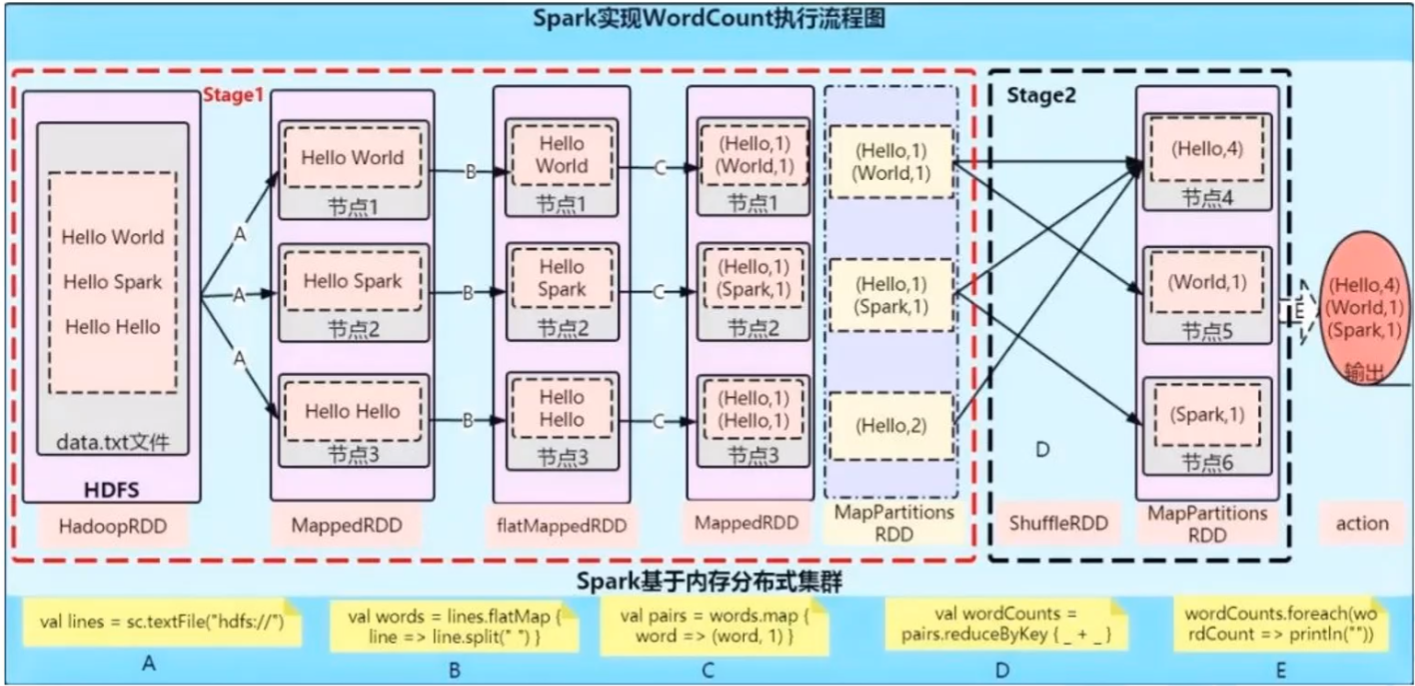
A.划分stage原因
- 数据本地化
- 移动计算,而不是移动数据
- 保证一个Stage内不会发生数据移动
B.Spark Shuffle过程
- 宽依赖就要shuffle
- 数据在shuffle中很有可能落盘
- 在分区之间重新分配数据
- 父RDD中同一分区中的数据按照算子要求重新进入子RDD的不同分区中
- 中间结果写入磁盘
- 由子RDD拉取数据,而不是由父RDD推送
- 默认情况下,Shuffle不会改变分区数量
C.依赖关系
- Lineage:血统、遗传
- 记录了RDD之前的转换操作和依赖关系
- 需要shuffle的都是宽依赖,带By的都是宽,join有可能宽有可能窄,distinct宽但有可能不是,要让内部的By不运行
- 要自己去改算子的先后以及其他方式提高效率。窄依赖的效率高
- 血统信息包括转换操作,依赖关系,数据流,执行计划,内存和磁盘的使用
6.数据倾斜
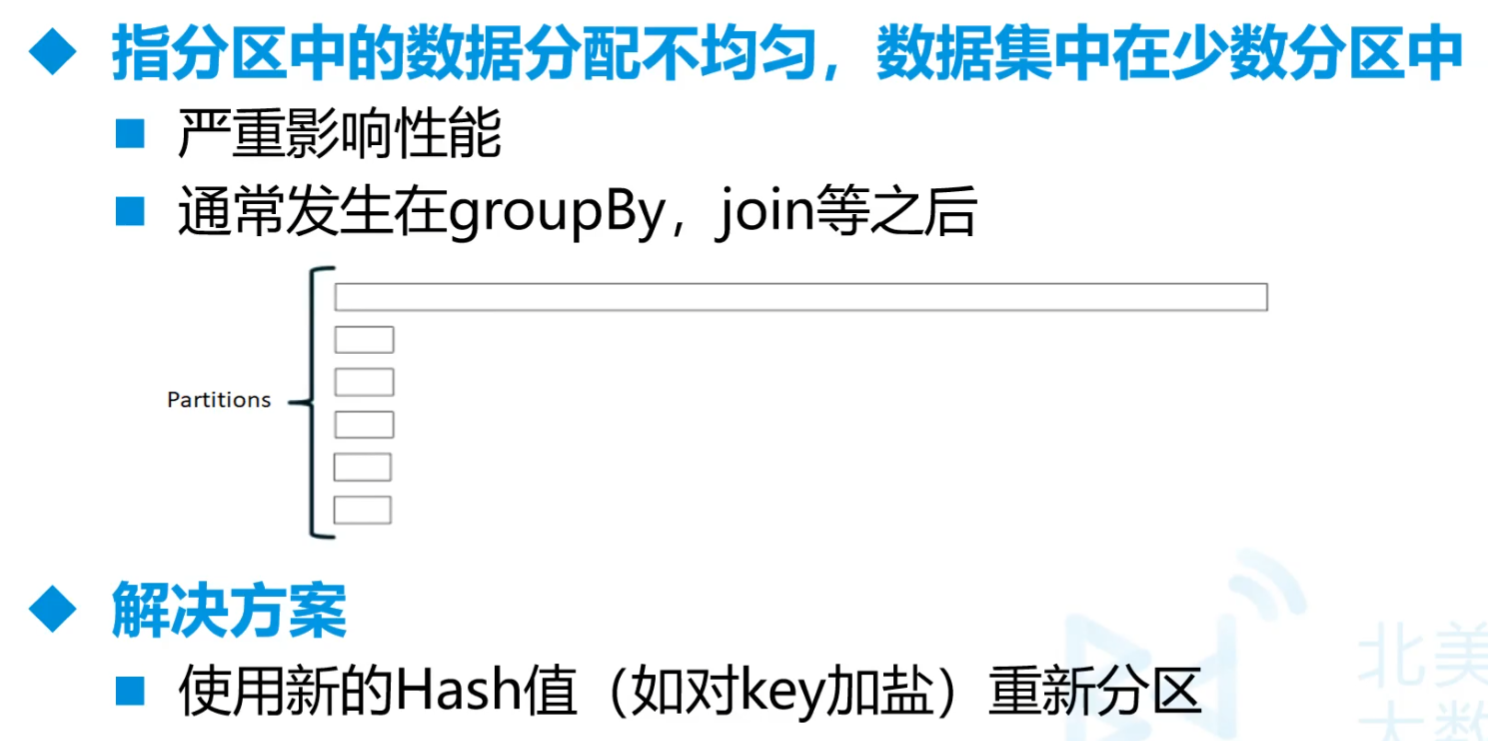
加盐加在前面,否则按照字典排序还是分不开
(三)安装
1.服务器安装(单机版)
- 该例子中所用的spark版本为
spark-2.3.4-bin-hadoop2.6.tgz
把相应包放到
/opt中命令执行
1
2
3
4
5
6cd /opt
tar -zxf spark-2.3.4-bin-hadoop2.6.tgz
mv spark-2.3.4-bin-hadoop2.6 soft/spark234
cd soft/spark234/conf
cp slaves.template slaves
cp spark-env.sh.template spark-env.shvim spark-env.sh1
2
3
4
5export SPARK_MASTER_HOST=192.168.179.139
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=3g
export SPARK_MASTER_WEBUI_PORT=8888vim ../sbin/spark-config.sh最后加1
export JAVA_HOME=/opt/soft/jdk180
在
/opt/soft/spark234/sbin中有启动的脚本,和Hadoop的脚本名重复启动与关闭
1
2
3
4cd /opt/soft/spark234/sbin
./start-all.sh
# 多出了Master和Worker
./stop-all.sh
(四)使用

1.第一次使用(idea/无环境)
A.导入包
1 | <dependency> |
B.导入scala的库
可以用之前的方法导入
也可以用这种方法
1
2
3
4
5<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>这边用原本的方法
C.使用Scala统计字数
- 正式写代码,最好使用.getOrCreate来建立,
val sc = SparkContext.getOrCreate(conf)
1 | object WordCount { |
D.使用Java统计字数
1 | import org.apache.spark.SparkConf; |
核心的那条语句可以改成
1 | words.flatMap(line-> Arrays.asList(line.split(" ")).iterator()) |
其中mapToPair可以告诉JVM我出了元组
2.程序提交服务器(发布)
两种模式
- Standalone
- yarn提交
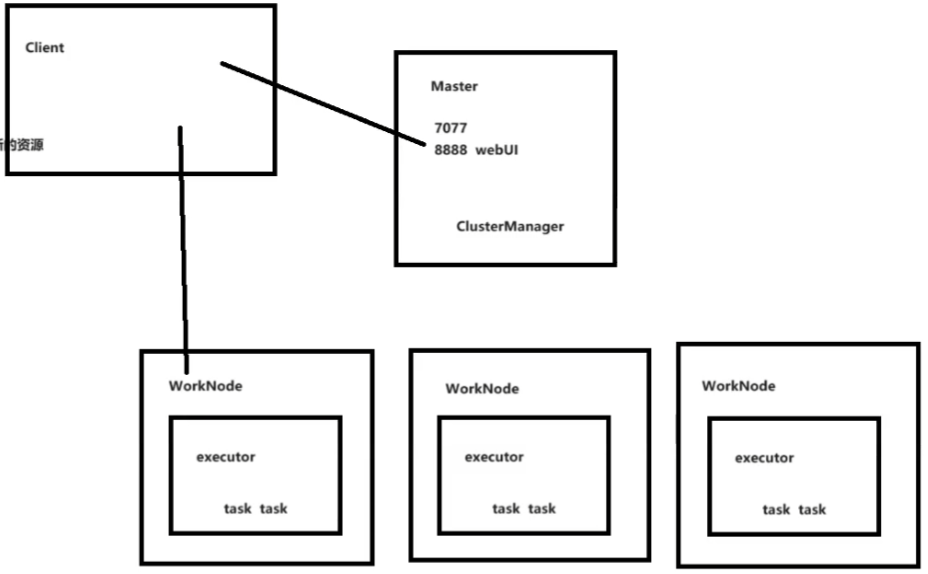
A.Standalone
Standalone : 无yarn操作
- Client通知Master提交任务
- Master将work资源推荐给Client
- Client找到WorkNode节点
- WorkNode开启一个Executor
- 资源不足则WorkNode会通知Client再找Master要新的资源
操作
建立相关Scala相关工程,写好相关代码
(不全的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<properties>
<scala.version>2.11</scala.version>
<spark.version>2.3.4</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>再pom.xml中build里面的全删了,在里面加入,这是用来打包瘦包的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>或者 用来打胖包的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 单词统计
case class MyWords(line:String)
object App {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("mytest").getOrCreate()
import spark.implicits._
val df = spark.createDataFrame(List(
MyWords("Hello World"),
MyWords("Hello Spark")
)).select(explode(split($"line"," ")).as("word"))
.groupBy("word").agg(count($"word").as("word_num"))
df.show()
spark.stop()
}
}Maven->clean->package
把打包的
mypacket-1.0-SNAPSHOT.jar拿出放入服务器中,在服务器上打开Hadoop、yarn和Spark。Master服务器提交
两种提交方式,一种为cluster一种是client,cluster会把把算子到各个节点,client会汇总到客户端
spark提交任务的几种方式_spark 提交模式-CSDN博客
1
2
3
4
5
6
7
8cd /opt/soft/spark234/bin/
./spark-submit \
--class com.njupt.mypackage.App \
--master spark://192.168.179.139:7077 \
--executor-memory 3G \
--total-executor-cores 4 \
--deploy-mode cluster \
/opt/mypacket-1.0-SNAPSHOT.jar1
2
3
4
5
6
7./spark-submit \
--class com.njupt.mypackage.App \ # 程序包路径
--master spark://192.168.179.139:7077 \ # Master地址
--executor-memory 3G \ # 单个executor内存
--total-executor-cores 4 \ # 总核数3个
--deploy-mode cluster \ # 使用--deploy-mode cluster参数提交作业时,意味着你希望Spark作业的驱动程序在集群中运行,而不是在提交作业的客户端机器上运行。这边结果给client,信息最后一定是在driver上看到的
/opt/mypacket-1.0-SNAPSHOT.jar # 包的主机中路径,后面可以跟参数
B.yarn服务器提交
先配yarn环境
1
2
3
4
5
6
7
8
9
10
11
12
13在/etc/profile中(要现有)YARN_HOME
上面已经有
export HADOOP_HOME=/opt/soft/hadoop260
export YARN_HOME=$HADOOP_HOME
下面要写
#Yarn Env
export YARN_CONF_DIR=$YARN_HOME/etc/hadoop
source /etc/profile
查看一下
# echo $YARN_CONF_DIR
/opt/soft/hadoop260/etc/hadoop代码注释掉
.master("local[*]")重打包,覆盖原本包命令
1
2
3
4
5
6
7
8cd /opt/soft/spark234/bin/
./spark-submit \
--class com.njupt.mypackage.App \
--master yarn \ # 改了这个
--executor-memory 3G \
--total-executor-cores 4 \
--deploy-mode client \ #改了这个 发布的时候还是要用cluster
/opt/mypacket-1.0-SNAPSHOT.jar
(五)基础学习
repartition设置分区个数
做全体排序的时候,要设置分区为1
1
2
3
4
5val infos = line.split(",")
(infos(2),infos(1))
}).groupByKey().mapValues(_.toList.size)
.repartition(1).sortBy(-_._2).take(5)
.foreach(println)
1.SparkSession
SparkSession的使用算子要有顺序,比如要先分组才能找到相应的聚合项
装载CSV数据源可用sql的语句,可以展示表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def main(args: Array[String]): Unit = {
// val conf = new SparkConf().setAppName("exp03").setMaster("local[*]")
// val sc = SparkContext.getOrCreate(conf)
//
// val rdd = sc.textFile("E:\\ProgramFile\\BigDataStudy\\data\\customer_details.csv")
// // 获取首行信息
// val first = rdd.first()
// // 通过过滤器去除首行
// rdd.filter(line => !line.equals(first)).take(5).foreach(println)
// sc.stop()
val spark = SparkSession.builder().master("local[*]")
.appName("exp03").getOrCreate();
// 读有表头的文件
val df = spark.read.option("header", true)
.csv("E:\\ProgramFile\\BigDataStudy\\data\\customer_details.csv");
// df.show();
// 给df起个名字
df.createTempView("customer")
// 尽心查询
spark.sql(
"""
|select count(*) s_name from customer where first_name like 'S%'
|""".stripMargin).show();
spark.stop();
}sql中的函数通过
import org.apache.spark.sql.functions._导入,要用spark.implicits._要先导入前面的包,这个spark不是绝对的,而是前面开启配置时的对象SparkSession后的算子
show(5,false)显示5行不剪切withColumn多加一列这儿是把这两列用空格的方式相连生成新一列
1
2df.withColumn("name",concat_ws(" ",
col("first_name"),col("last_name"))).show(5)withColumnRenamed改列名1
df.withColumnRenamed("first_name","fname").show();
toDF变为DataFrame,起列名1
2
3val df1 = spark.read.csv("E:\\ProgramFile\\BigDataStudy\\data\\customers.csv")
.toDF("id","fname","lname","xxx","xxx1","address","area","ar","num")
.show(5)RDD转DataFrame
1
2
3// 必须紧跟在toDF上
import spark.implicits._
spark.sparkContext.parallelize(Seq((1,"zs"),(2,"ls"))).toDF("id","name").show()orderBy排序倒叙前5
1
df.orderBy(col("customer_id").desc).show(5);
where和like三种方法
1
2
3
4
5
6df.where("first_name like 'Z%'").show()
df.where(col("first_name").like("Z%")).show(5) // 效果相同
// 效果也相同
import spark.implicits._
df.where($"first_name".like("Z%")).show(5)lit相当于做了一个小表一行一列===是等于1
2import spark.implicits._
df.where($"first_name"===lit("Zachariah")).show(5)and条件相连1
df.where($"first_name".like("Z%") and $"gender"===lit("Female")).show(5)
select选择投影1
df.select($"first_name".as("fanme"),$"last_name".as("lname"),$"email").show(5)
as改别名
1
2import spark.implicits._
df.select($"first_name".as("fanme"),$"last_name".as("lname"),$"email").show(5)joininner join,要左右外联,只要把inner改left或right1
2
3custdf.join(transdf,custdf("customer_id")===transdf("customer_id"),"inner")
// 列名一样可以用一下的方式相关联
custdf.join(transdf,Seq("customer_id"),"inner").show(5)crossJoin笛卡尔集groupBy分组,聚合函数1
transdf.groupBy($"customer_id").agg(sum($"price").as("totalprice"),count($"product").as("paynum")).show(5)
Windows.partitionedby
Windows窗口函数
rank().over(Window.orderBy(desc("event_num")))但凡有null的地方补为0
1
.na.fill(0)
2.装载JSON
3.Spark SQL架构
- 介绍
- 提高了更高层次的接口方便地处理数据
- 是Spark的核心组件,能够直接访问现存的hive
- 支持SQL、API编程
-
- 主要是SparkSession
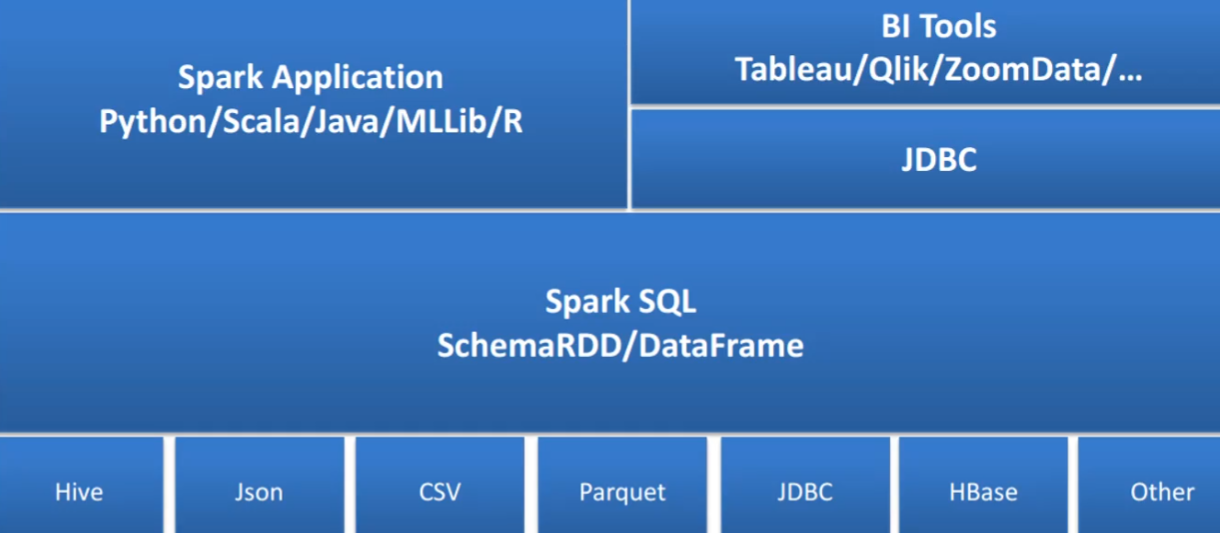
 - 主要是SparkSession
- 主要是SparkSessionA.DataSet

B.DataFrame

C.Spark SQL 函数
内置函数
自定义函数
Java中有LocalDate来转为星期
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19object Exp04 {
// 自定义UDF
val myDayOfWeek=udf((time:String)=>{
LocalDate.parse(time.split(" ")(0)).getDayOfWeek.toString
})
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("exp04").getOrCreate();
val ordDF = spark.read.csv("E:/Temp/retail_db/orders.csv")
.toDF("ordid", "orddate", "userid", "statu")
val itemDF = spark.read.csv("E:/Temp/retail_db/order_items.csv")
.toDF("itemid", "ordid", "productid", "buynum", "cntprice", "price")
import spark.implicits._
ordDF.join(itemDF,Seq("ordid")).select($"ordid",
myDayOfWeek($"orddate").as("weekday"),$"buynum")
.groupBy("weekday").agg(sum("buynum").as("cnt_buynum"))
.show()
spark.stop();
}
}
E.操作外部数据源
- PostgreSQL建议自学一下

连接MySQL
导入包
1
2
3
4
5<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>连接取数据
- 读:
spark.read.jdbc(url, 表名, param)
1
2
3
4
5
6
7
8
9
10
11
12
13
14object Exp05 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("exp05").getOrCreate();
// 读取数据库
val param = new Properties()
param.setProperty("user","root")
param.setProperty("password","ok")
param.setProperty("driver","com.mysql.jdbc.Driver") // mysql5 8要在mysql后加cj
val url = "jdbc:mysql://192.168.179.139:3306/exp"
val custDF = spark.read.jdbc(url, "customers", param)
custDF.show()
spark.stop()
}
}写
custDF.write.mode(SaveMode.Append).saveAsTable("products")SaveMode.OverWrite属性,要填入写样例类,并且用DF传入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20case class Products(productid:Int,typeid:Int,title:String,
orginprice:Double,imgs:String);
object Exp05 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("exp05").getOrCreate();
// 读取数据库
val param = new Properties()
param.setProperty("user","root")
param.setProperty("password","ok")
param.setProperty("driver","com.mysql.jdbc.Driver") // mysql5 8要在mysql后加cj 下面的url也要加相关配置
val url = "jdbc:mysql://192.168.179.139:3306/exp"
// val custDF = spark.read.jdbc(url, "products", param)
val df = spark.createDataFrame(List(Products(1500, 1, "中国商品", 1000.12, "http://imgs/123.jpg")))
df.write.mode(SaveMode.Append).jdbc(url, "products", param)
// custDF.show()
spark.stop()
}
}
- 读:
连接Hive
导入包
要对应好hive和spark版本
1
2
3
4
5<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.4</version>
</dependency>代码
- 读
9083端口
1
2
3
4
5
6
7
8
9
10
11
12object Exp06 {
def main(args: Array[String]): Unit = {
var spark=SparkSession.builder().appName("exp06")
.master("local[*]")
.config("hive.metastore.uris","thrift://192.168.179.139:9083")
.enableHiveSupport()
.getOrCreate()
val df = spark.sql("select * from exp.cust")
df.show()
spark.stop()
}
}写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16case class Custs(id:String,name:String);
object Exp06 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root") // 写的时候要设置用户
var spark=SparkSession.builder().appName("exp06")
.master("local[*]")
.config("hive.metastore.uris","thrift://192.168.179.139:9083")
.enableHiveSupport()
.getOrCreate()
// val df = spark.sql("select * from exp.custs")
val df = spark.createDataFrame(List(Custs("4", "zl")))
df.write.format("Hive").mode(SaveMode.Append).saveAsTable("exp.custs") // 文本格式要默认为Hive的
// df.show()
spark.stop()
}
}
连接Hbase
导入包
1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0</version>
</dependency>读
导包要注意
spark.sparkContext那段不知道是什么
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.{Row, SparkSession}
case class Users(userid:String,uname:String,gender:String,say:String)
object Exp07 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("exp07")
.master("local[*]")
.getOrCreate()
val config = HBaseConfiguration.create()
config.set("hbase.zookeeper.quorum","192.168.179.139:2181")
config.set(TableInputFormat.INPUT_TABLE,"mydemo:users")
val rdd=spark.sparkContext.newAPIHadoopRDD( // <-------------
config,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
import spark.implicits._
val arrRDD = rdd.map {
case (_, result) => {
val key = Bytes.toString(result.getRow)
val uname = Bytes.toString(result.getValue("base".getBytes(), "uname".getBytes()))
val gender = Bytes.toString(result.getValue("base".getBytes(), "gender".getBytes()))
val say = Bytes.toString(result.getValue("base".getBytes(), "say".getBytes()))
Users(key, uname, gender, say)
}
}.toDF()
// // 做一个表的元数据结构
// val tabSchema = StructType(Seq(
// StructField("userid", StringType),
// StructField("uname", StringType),
// StructField("gender", StringType),
// StructField("say", StringType)
// ))
arrRDD.show(false)
spark.stop()
}
}写
这边要注意写入要foreachPartition,因为Hbase驱动在Driver Program端,而塞数据在Executor中,table和conn都是接口,无法序列化传输
后期再用数组作为缓存,一次性放入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41package com.njupt.spark001
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{ConnectionFactory, Put}
import org.apache.spark.sql._
import scala.collection.mutable.ListBuffer
case class Users(rk:Int,uname:String)
object Exp07 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("exp07")
.master("local[*]")
.getOrCreate()
// 写数据
val data= ListBuffer[Users]()
for(k:Int <- 1000 to 2000){
Users(k,s"test${k}")+=:data
}
val df: DataFrame = spark.createDataFrame[Users](data).repartition(5)
// 创建hbase连接
df.foreachPartition(partition=> {
//一个分区开一次连接
val config = HBaseConfiguration.create()
config.set("hbase.zookeeper.quorum","192.168.179.139:2181")
val conn = ConnectionFactory.createConnection(config)
val table = conn.getTable(TableName.valueOf("mydemo:uuu"))
partition.foreach(row => {
val put = new Put(row.getAs("rk").toString.getBytes())
put.addColumn("base".getBytes(),"uname".getBytes()
, row.getAs("uname").toString.getBytes())
table.put(put)
})
table.close()
conn.close()
})
spark.stop()
}
}
写入文件
1个分区,有头
1
resDF.coalesce(1).write.option("header","true").mode(SaveMode.Overwrite).csv(param.get("write_file_path").get)
4.Spark Machine Learning架构
(1)
1 | <dependency> |
(2)
(3)
(4)离线项目
- 工程名spkmodel
Spark ML 之 KMeans算法的应用实操——用户分群召回推荐算法
(六)进阶学习
1.性能优化
A.序列化

1 | case class MyWords(line:String) |
B.性能优化2
- 使用对象数组、原始类型代替Java、Scala集合类(如HashMap)
- 避免嵌套结构
- 尽量使用数字作为Key,而非字符串
- 以较大的RDD使用MEMORY ONLY SER
- 加载CSV、JSON时,仅加载所需字段
- 仅在需要时持久化中间结果(RDD/DS/DF)
- 避免不必要的中间结果(RDD/DS/DF)的生成
- DF的执行速度比DS快约3倍
C.性能优化3
- 自定义RDD分区与spark.default.parallelism
- 该参数用于设置每个stage的默认task数量
- 将大变量广播出去,而不是直接使用
- 尝试处理本地数据并最小化跨工作节点的数据传输
D.性能优化4

起别名效率高,因为会有映射
最后
- 标题: 大数据学习笔记4-Spark
- 作者: Sabthever
- 创建于 : 2025-07-08 20:02:34
- 更新于 : 2025-10-09 16:14:31
- 链接: https://sabthever.cn/2025/07/08/technology/bigdata/Hadoop4-Spark/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
