大数据学习笔记3-Scala

Hadoop3
九.Scala
(一)前期
- 数据分析专用语言
- 源自Java
- 构建在JVM上
- 与Java兼容、互通
- 优势
- 多范式编程:面向对象、函数式
- 表达能力强,代码精简
- 大数据Scala
- Spark采用Scala语言设计
- 提供的API更加优雅
- 基于JVM的语言更融入Hadoop生态圈
(二)内容介绍
- 一般要idea和终端配合使用


(三)开发环境搭建
- 2.11.8版本配合后面Spark
语言安装
对于scala-2.11.8.msi,一路往后next就行了
进入cmd
scala看是否能用
idea中安装插件
联机安装,在前面的界面中Plugins找Scala插件install
离线安装,自己找方法去,找到zip和jar后(要对应好idea的相应版本),Settings->Plugins->Install plugin from disk
(四)基础语法
1.初次使用
A.建立idea scala工程
- 仍然使用Maven-quickstart,因为Scala的选项全用国外源
- 三处版本改好
- 在main中右键新建一个scala目录
- 右击scala目录,Mark Directory As->Resources Root
- alt ctrl shift s ->Libraries->+号->加入scala-sdk->ok->ok
B.第一个Scala对象
右击scala包,scala class->
com.njupt.firstscala.First要选Objectmain回车会直接跳出来,写下hello world
1
2
3
4
5
6
7package com.njupt.firstscala
object First {
def main(args: Array[String]): Unit = {
println("Hello,world!!!")
}
}Unit那是返回值,相当于void,=是固定语法
调用Java中的函数
- scala调用Java
1
2
3
4
5
6public class App1
{
public void kkk(String name) {
System.out.println(name+"你好");
}
}1
2
3
4
5
6
7object First {
def main(args: Array[String]): Unit = {
val app = new App1();
app.kkk("张三丰");
println("Hello,world!!!");
}
}Java调用Scala
1
2
3
4
5object First {
def xxx(name:String):String={
return name+",你坏!!";
}
}1
2
3
4
5
6
7
8public class App1
{
public static void main( String[] args )
{
System.out.println( "Hello World!" + First.xxx("张无忌") );
}
}First是一个对象,不用创建直接调用
c.流式语法初试
对于数组每一个加2,过滤出偶数,然后逐行输出
1
2
3
4def main(args: Array[String]): Unit = {
val arr=Array(1,22,13,56,78,77);
arr.map(x=>x+2).filter(x=>x%2==0).foreach(println);
}
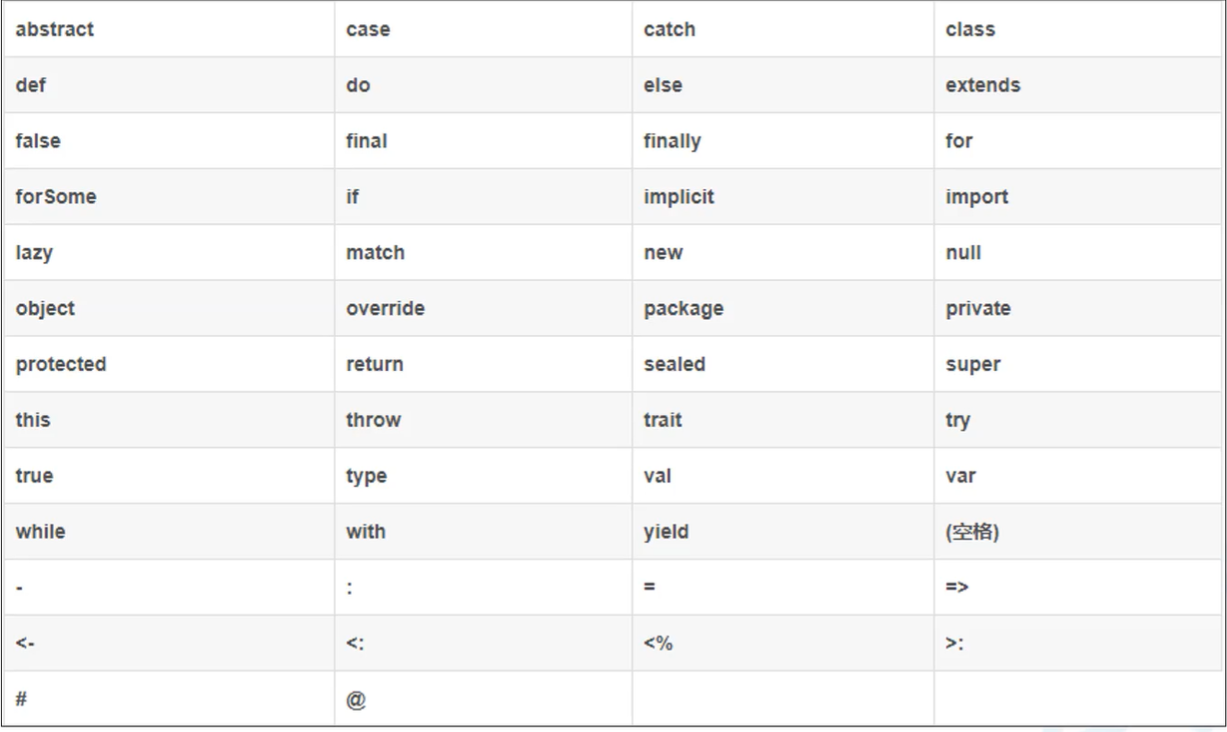
2.关键字表
3.变量与常量
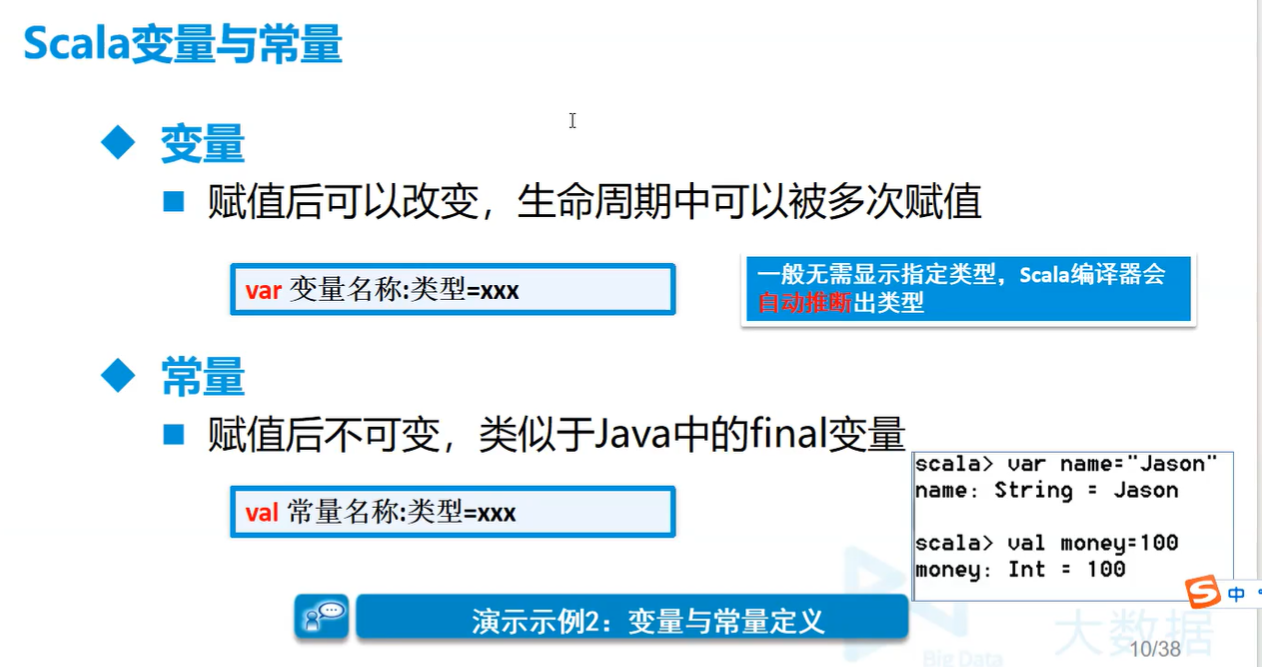
例子 变量
1
2var a:Int=10;
var a=10; // 也行例子 常量
1
2val b:Int=20;
val b=20; // 也行内部有类型识别器会自动识别
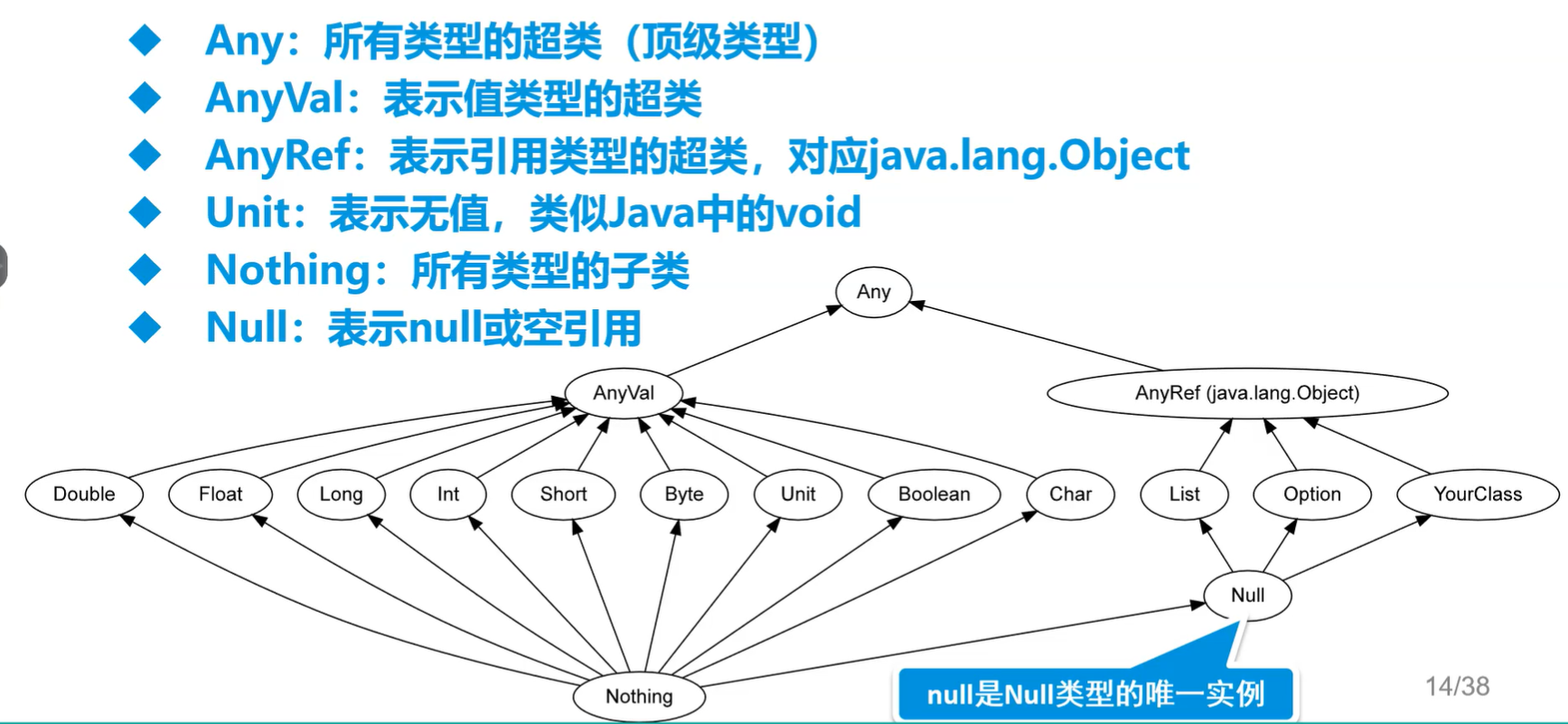
4.数据类型
A.包装类型
- Scala认为一切皆对象,因此首字母全都是大写,比Java还纯粹,Java中是基本类型,Scala是包装类型。
- 变量底下有很多很多方法,连基本运算都是方法。
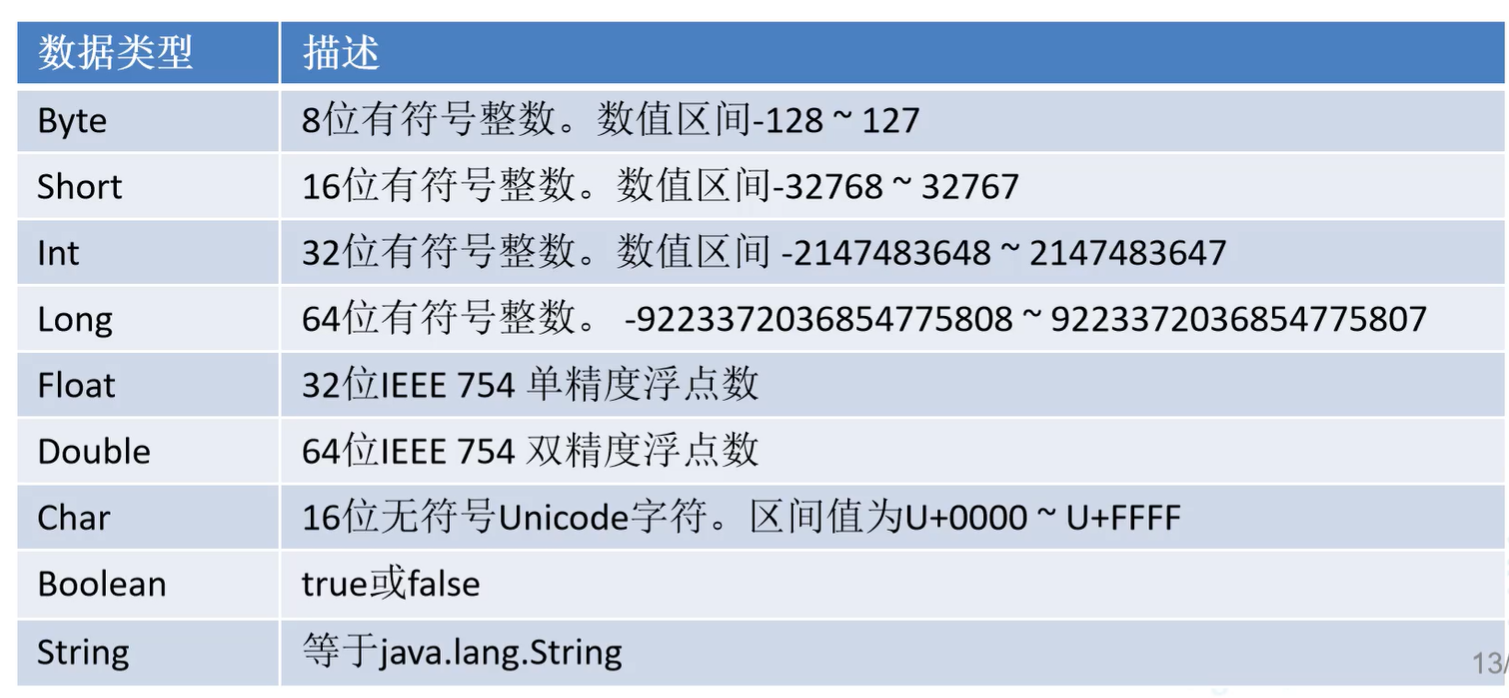
B.数据类型层次结构
图
5.字符串插值器
s型插值器
1
2
3
4var name="张三";
var name2="李四";
println(s"${name}和${name2}是朋友")
// 结果:张三和李四是朋友

6.判断语句
A.if语句
和Java一样直接用
并且支持如下语法,Scala中不支持三元表达式
1
2
3var num=20;
var res = if(num%2==0) 1 else 2;
println(res);
B.while
- 和Java一样用,
do...while也没有区别
C.for循环
图
to是
1<=i<=numuntil是
1<=i<numby后面跟着的是步长
1
2
3
4// 这是10-5输出 步长为-1
for(g:Int <- 10 to 5 by -1) {
println(g);
}<-这个是个组合符号foreach用法
1
2
3
4val arr=Array(1,22,13,56,78,77);
for(i:Int <- arr) {
println(i)
}for循环过滤
1
2
3
4for(i:Int <- 1 to 10 ; if i%2==0) {
print(i);
}
// 输出246810后面可以跟着多条件,这些条件相当于是&&的关系
1
for(i:Int <- 1 to 10 ; if 条件1; if 条件2……){}

D.中断
break
要导入包才可以用
1
2
3
4
5
6
7
8
9
10
11
12
13import scala.util.control.Breaks.break
for(i:Int <- arr) {
if(i%2!=0) break;
print(i+" ")
}
//或者break()也行,但是不管怎么样都会抛出错误,因此应该
import scala.util.control.Breaks.{break, breakable}
breakable{
for(i:Int <- arr) {
if(i%2!=0) break;
print(i+" ")
}
}breakable相当于规定了跳转的位置
因此可以如下替代continue的用法,scala中没有continue
1
2
3
4
5
6for(i:Int <- arr) {
breakable{
if(i%2!=0) break();
print(i+" ")
}
}
E.match
相当于Java 的switch,但是功能有增强。_相当于其他
1 | scala> arr.groupBy(x=>{ |
模式匹配
- 模式后面加if是模式守卫
可用于类型判定
可用于样例类内部值直接判定
- 例1 找到了sid为”zs”的,并且提取了他的birthday,gender值
1
2
3
4
5
6val zs = Student("1", "zs", "1999-10-12", "男")
zs match{
case Student(sid,"zs",birthday,gender)=>println(s"看到张三了${birthday}")
case _=>println("没有找到")
}
// 看到张三了1999-10-12- 例2 模式守卫
1
2
3
4zs match{
case Student(sid,"zs",birthday,gender) if birthday.toInt>=10 =>println(s"看到张三了${birthday}")
case _=>println("没有找到")
}- 例3 由这个知道,样例类自带unapply,但是普通类没有,需要自己去实现。而match匹配输出靠的就是unapply
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class Customer (_name:String,_age:Int){
val name=_name;
val age=_age;
}
object Customer{
def apply(_name: String, _age: Int): Customer = new Customer(_name, _age)
// def unapply(arg: Customer): Option[(String, Int)] = {
// if(arg ==null)
// None
// else
// Some(arg.name,arg.age)
// }
// 没这个就会出下面的错误
}
object MyTest {
def main(args: Array[String]): Unit = {
val customer = Customer("zs", 20)
customer match {
case Customer(name,age) =>println(s"${name},${age}") // 这边出错了,找不到unapply
case _=>println("not found")
}
}
}



7.Scala函数

- 不用return ,直接把要返回的内容放最下面
- 函数字面量其实就是函数名,类字面量是类的属性
A.参数传递与高阶函数
传值调用(call-by-value) 传名调用(call-bh)
高阶函数:参数可以为函数
1
2
3
4
5
6
7
8
9
10
11
12
13object Demo {
def abc(f:(String,Int) =>String) ={
val res = f("李四", 20)
println(res)
}
def ab(x:String,y:Int):String={
"Hello,"+x+","+y.toString
}
def main(args: Array[String]): Unit = {
abc(ab)
}
}
// 输出 Hello,李四,20 abc是高阶函数f:(String,Int) =>String代表,传入的参数是个函数,(String,Int)是传入函数的参数列表,=>String,这一段成为ab的方法原型上面图中
f:=>Int是传入无参函数,输出为Int类型

B.参数可设置默认值
1 | def ab(x:String="pty",y:Int=13):String={ |
C.匿名函数
1 | def abc(f:(String,Int) =>String) ={ |
abc包括的部分,如下,就是匿名函数,实际上就是Java中的Lambda表达式
1
2
3(x,y)=>{
s"Hello,${x},${y}"
}
D.函数嵌套
- 函数里可以包含方法,但是出了外层就不可用了
- 不建议使用
E.函数柯里化
每个参数都加个小括号
1
2
3
4
5
6
7def mod(n:Int)(n2:Int):Int={
n+n2
}
def main(args: Array[String]): Unit = {
println(mod(10)(20))
}可用于方法重载
1
2
3
4
5
6
7
8
9def mod(n:Int)(n2:Int)={
n+n2
}
def mod1(n:Int)=mod(n)(20)
def mod2(n2:Int)=mod(10)(n2)
def main(args: Array[String]): Unit = {
println(mod1(10))
}
F.隐式参数

不管是全局还是局部只能有一个类型相似的隐式参数,如在这儿是个Int型,那么整个类中只能有这一个Int型的隐式参数
和柯里化结合,会对最后一整个小括号里所有生效
例子
1
2
3
4
5
6
7
8
9
10
11
12object CurryingTest {
implicit var abc:Int=20 // 不管全局还是局部一个类中只能一个同类型的隐式参数
def mod(n:Int)(implicit n2:Int)={
n+n2
}
def main(args: Array[String]): Unit = {
println(mod(10)) // 出30
println(mod(10)(40)) // 出50
}
}隐藏了方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Tools {
def genericNum(str:String,i:Int)={
str.hashCode()%i
}
}
object CurryingTest {
implicit var abc1:Tools=new Tools()
def mod(str:String)(implicit gn:Tools) = {
gn.genericNum(str,3)
}
def main(args: Array[String]): Unit = {
println(mod("hello"))
}
}
G.隐式函数
隐式函数也称隐式转换,使用implicit修饰的函数
应用场景
例子
本来
true+20是不可以的,但是隐式函数让Boolean类型的直接转换了1
2
3
4
5
6
7
8implicit def fti(x:Boolean)=if(x) 1 else 0
def main(args: Array[String]): Unit = {
// println(mod("hello"))
var flag=true;
var num=20;
println(flag+num)
}任何值无法执行都变为数字,只有出错时才会调用隐式函数
1
implicit def stn(x:Any)=x.toString.toInt

H.函数闭包
变量型的函数
1
2
3
4
5def abc=(str:String)=>{
s"Hello,${str}"
}
println(abc("sfdf"))
// Hello,sfdf尽量不要用
(五)数组、元组与集合
- scala中的语法:方法中只有一个参数可以省略
.和() - Map往往要用二元组来变化或者输出
- scala算子,类似于流处理
String*类型的传值除了"a","b",还可以数组:_*
1.数组
这边用的都是小括号来判断
-
在终端中看
1
2val arr=Array(1,2,3,656,32,76,1)
arr.按Tab迭代器用foreach来读取,Some(1)诸如此类用get来获取
def ++[B >: Int, That](that: scala.collection.GenTraversableOnce[B])(implicit bf: scala.collection.generic.CanBuildFrom[Array[Int],B,That]): ThatB和That都是泛型,但B要至少Int型的,即为Long。byte和short不可用。后面跟着个集合。集合的合并
- 下面包括的其他知识点:
- 偏函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37arr.++(Array(3,5,7))
//输出res0: Array[Int] = Array(1, 2, 3, 656, 32, 76, 1, 3, 5, 7)
arr.++(Array("aa","bb"))
// 输出res1: Array[Any] = Array(1, 2, 3, 656, 32, 76, 1, aa, bb)
arr ++ Array("aa","bb")
// res2: Array[Any] = Array(1, 2, 3, 656, 32, 76, 1, aa, bb)
arr ++ "cc"
// res3: Array[AnyVal] = Array(1, 2, 3, 656, 32, 76, 1, c, c)
arr ++ 100
// 错误输出
scala> 10 +: arr
res6: Array[Int] = Array(10, 1, 2, 3, 656, 32, 76, 1)
scala> arr :+ 10
res7: Array[Int] = Array(1, 2, 3, 656, 32, 76, 1, 10)
scala> lst ++: arr
res8: Array[Int] = Array(4, 5, 68, 90, 1, 2, 3, 656, 32, 76, 1)
scala> arr++: lst
res9: List[Int] = List(1, 2, 3, 656, 32, 76, 1, 4, 5, 68, 90)
//**`:`在的位置即为数组在的位置**,冒号右边的集合决定最终的结合
// 光++也可以,而且以左边的为最终类型
(0 /: arr)(_+_)
res10: Int = 771 // 左子树相加,把数组里的内容全部相加
(1 /: arr)(_*_)
res12: Int = 9572352 // 左子树相乘,把数组里的内容全部相乘,前面的值是初始值
(arr :\ 0)(_+_)
res13: Int = 771 // 右子树相加,从右加到左
scala> val sbi = new StringBuilder()
sbi: StringBuilder =
scala> arr.addString(sbi)
res14: StringBuilder = 12365632761 // 化为字符串相连
scala> arr.mkString(",")
res15: String = 1,2,3,656,32,76,1 // 转为字符串,而且还可以设置分隔符:始终对着集合- 下面包括的其他知识点:
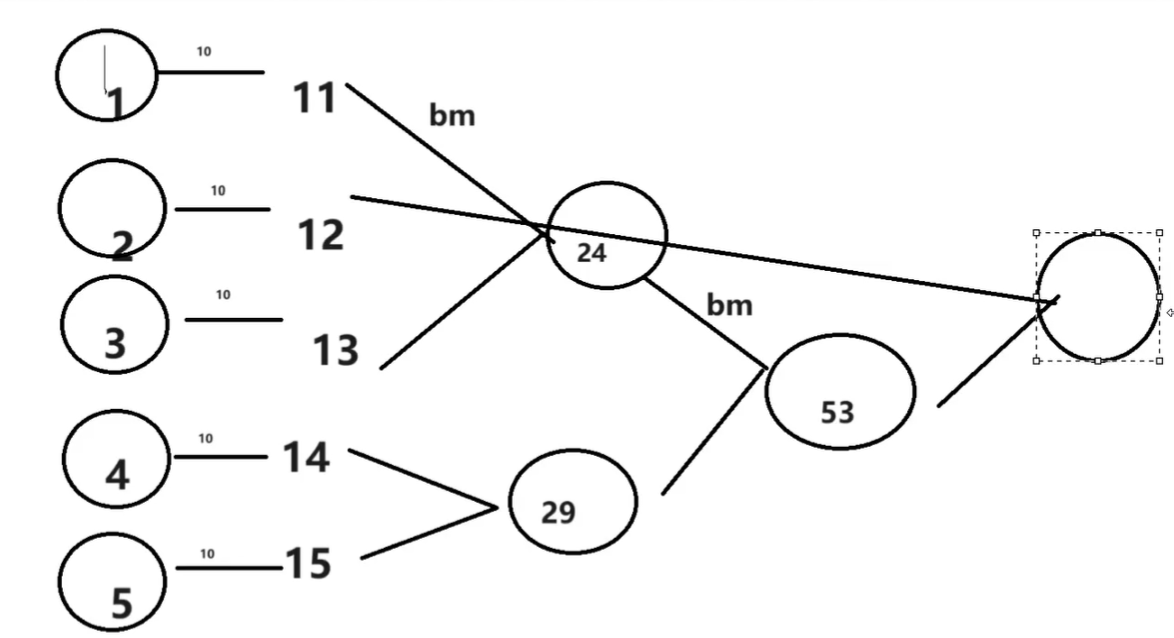
arr1.par.aggregate(10)(am,bm)10会成为第一个函数的第一个参数,每一个值是第一个函数中第二个值。第二个函数是前面计算结果的数组中的所有值,是多线程,一定要加这个par1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63scala> val arr1=Array(1,2,3,4,5)
arr1: Array[Int] = Array(1, 2, 3, 4, 5)
scala> def am(num1:Int,num2:Int):Int={
| println(s"${num1}+${num2}")
| return num1+num2;
| }
am: (num1: Int, num2: Int)Int
scala> def bm(num1:Int,num2:Int):Int={
| println(s"bm:${num1}+${num2}=${num1+num2}")
| return num1+num2;
| }
bm: (num1: Int, num2: Int)Int
scala> arr1.aggregate(10)(am,bm)
10+1
11+2
13+3
16+4
20+5
res16: Int = 25
scala> arr1.par.aggregate(10)(am,bm)
// 下面这些顺序都不一定
10+4
10+2
10+3
10+1
10+5
bm:11+12=23
bm:14+15=29
bm:13+29=42
bm:23+42=65
res17: Int = 65
// 上面这些过程,可以简化为下面的
scala> arr1.par.aggregate(10)(_+_,_+_)
res48: Int = 65
// 但是结果不一定为65出错,因为多线程太快了,而前面的每步骤print减缓了速度,大部分情况都是对的
//apply 取值操作
scala> arr1(2)
res83: Int = 3
scala> arr1.apply(2)
res84: Int = 3
//charAt 按数字取字符
var str=Array('a','c','d')
str: Array[Char] = Array(a, c, d)
scala> str.charAt(1)
res85: Char = c
// 赋值只是地址
scala> var arr2=arr1
arr2: Array[Int] = Array(1, 2, 3, 4, 5)
scala> arr2(2)=100
scala> arr1
res89: Array[Int] = Array(1, 2, 100, 4, 5)
// 用clone()就会出新的
scala> val arr2=arr1.clone()
arr2: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr2(1)=44
scala> arr1
res91: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr2
res92: Array[Int] = Array(1, 44, 100, 4, 5)collect,内部为偏心函数
PartialFunction,只要某些值 可对多种不同的if内部数据进行处理和输出。只处理部分1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170// 只要偶数,并且将偶数*10
scala> arr1
res93: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.collect{case x if(x%2==0)=>x*10}
res94: Array[Int] = Array(20, 1000, 40)
scala> arr1.collect({case x if(x%2==0)=>x*10})
res95: Array[Int] = Array(20, 1000, 40)
// 使用偏心函数
scala> val pianxin:PartialFunction[Int,Int]={
| case x if(x%2==0) => x*10
| case x=>x+3
| }
pianxin: PartialFunction[Int,Int] = <function1>
scala> arr1.collect(pianxin)
res96: Array[Int] = Array(4, 20, 1000, 40, 8)
scala> arr1.collect({case x if(x%2==0)=>x*10 case x if(x%2==1)=>x*100000})
res97: Array[Int] = Array(100000, 20, 1000, 40, 500000)
// combinations是将数据按照括号中的数字进行组合,这边是两两组合,出来是个迭代器
scala> arr1.combinations(2).foreach(x=>println(x.mkString(",")))
1,2
1,100
1,4
1,5
2,100
2,4
2,5
100,4
100,5
4,5
// 是否在数组中
scala> arr1.contains(100)
res101: Boolean = true
scala> arr1.contains(101)
res102: Boolean = false
// 查找序列,而且必须连续,不可相反,必须一模一样
scala> arr1
res103: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.containsSlice(List(100,2))
res104: Boolean = false
scala> arr1.containsSlice(List(2,100))
res105: Boolean = true
// 数组拷贝
scala> arr1
res106: Array[Int] = Array(1, 2, 100, 4, 5)
scala> val arr3=new Array[Int](10)
arr3: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
scala> arr1.copyToArray(arr3,2,3)
scala> arr3
res108: Array[Int] = Array(0, 0, 1, 2, 100, 0, 0, 0, 0, 0)
//copyToBuffer 拷贝到集合中
scala> import scala.collection.mutable.Buffer
import scala.collection.mutable.Buffer
scala> val bf = Buffer[Int]()
bf: scala.collection.mutable.Buffer[Int] = ArrayBuffer()
scala> arr1.copyToBuffer(bf)
scala> bf
res113: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 100, 4, 5)
//corresponds 相同数量序列元素一一对比大小,是否符合条件
scala> arr1
res115: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr2
res116: Array[Int] = Array(1, 44, 100, 4, 5)
scala> arr1.corresponds(arr2)(_==_)
res117: Boolean = false
scala> arr1.corresponds(arr2)(_<=_)
res118: Boolean = true
//count 统计符合条件的总数
scala> arr2.count(x=>x%2==0) // 偶数
res119: Int = 3
scala> arr2.count(x=>true) // 全部
res120: Int = 5
// arr2.size也是统计整个长度
//diff 计算当前数组与另一个数组的不同。将当前数组中没有在另一个数组中出现的元素返回
scala> val arr4=Array(1,100,6,7,99)
arr4: Array[Int] = Array(1, 100, 6, 7, 99)
scala> arr1
res121: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.diff(arr4)
res122: Array[Int] = Array(2, 4, 5) // arr1中4没有的
scala> arr1.diff(arr4) ++: arr4.diff(arr1)
res123: Array[Int] = Array(2, 4, 5, 6, 7, 99)// 两张表中不同的部分
//distinct 去重
scala> val arr5=Array(1,2,1,1,235)
arr5: Array[Int] = Array(1, 2, 1, 1, 235)
scala> arr5.distinct
res125: Array[Int] = Array(1, 2, 235)
//drop 功能同 drop,去掉开头几个。dropRight去掉尾部的 n 个元素
scala> arr1
res126: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.dropRight(2)
res127: Array[Int] = Array(1, 2, 100)
//dropWhile 只删到第一个不满足条件的数据
arr1.dropWhile(x=>x<50)
res128: Array[Int] = Array(100, 4, 5)
scala> arr1.dropWhile(x=>x<2)
res129: Array[Int] = Array(2, 100, 4, 5)
scala> arr1.dropWhile(x=>x<4)
res130: Array[Int] = Array(100, 4, 5)
//endsWith 是否以某个序列结尾
scala> arr1.endsWith(List(4,5))
res131: Boolean = true
//exists 是否存在符合条件的
scala> arr1
res126: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.exists(x=>x>100)
res133: Boolean = false
scala> arr1.exists(x=>x>50)
res134: Boolean = true
//filter和filterNot 满足条件和不满足的
scala> arr1
res126: Array[Int] = Array(1, 2, 100, 4, 5)
scala> arr1.filter(x=>x%2==0)
res135: Array[Int] = Array(2, 100, 4)
scala> arr1.filterNot(x=>x%2==0)
res136: Array[Int] = Array(1, 5)
//find 第一个满足条件的
scala> arr1.find(x=>x>3)
res137: Option[Int] = Some(100)
scala> arr1.find(x=>x>100)
res140: Option[Int] = None
//flatten 多为数组降维
scala> var twoarr=Array(Array(1,2,3),Array(4,5,6))
twoarr: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6))
scala> twoarr.flatten
res141: Array[Int] = Array(1, 2, 3, 4, 5, 6)
//flatMap 相当于map再flatten
scala> val words=Array("Hello world", "Hello spark")
words: Array[String] = Array(Hello world, Hello spark)
scala> words.map(line=>line.split(" "))
res143: Array[Array[String]] = Array(Array(Hello, world), Array(Hello, spark))
scala> words.map(line=>line.split(" ")).flatten
res144: Array[String] = Array(Hello, world, Hello, spark)
scala> words.flatMap(line=>line.split(" "))
res145: Array[String] = Array(Hello, world, Hello, spark)
// scala中使用map,map中用Some包裹返回时返回None就没有返回
// 分组统计单词 元组tuple用_1,_2来出数据,map后flatten
scala> words.flatMap(line=>line.split(" ")).groupBy(x=>x).foreach(x=>println(x._1,x._2.size))
(spark,1)
(world,1)
(Hello,2)
scala> arr.groupBy(x=>{
| if(x%2==0){
| "even"
| }else{
| "odd"
| }
| })
res0: scala.collection.immutable.Map[String,Array[Int]] = Map(odd -> Array(1, 3435, 89), even -> Array(22, 56, 8))
match相当于Java 的switch,但是功能有增强。
_相当于其他。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385scala> arr
res6: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
// groupBy加match
scala> arr.groupBy(x=>{
| x match {
| case i if i%2==0 => "even"
| case _ => "odd"
| }
| })
res2: scala.collection.immutable.Map[String,Array[Int]] = Map(odd -> Array(1, 3435, 89), even -> Array(22, 56, 8))
scala> arr.groupBy(x=>x match{
| case i if i%2==0 => "even"
| case _ => "odd"
| })
res3: scala.collection.immutable.Map[String,Array[Int]] = Map(odd -> Array(1, 3435, 89), even -> Array(22, 56, 8))
// 按几个元素分组
scala> arr
res6: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.grouped(3).foreach(x=>println(x.mkString(",")))
1,22,3435
56,8,89
// 判断是否有界限,流是没有界限的
scala> arr.hasDefiniteSize
res8: Boolean = true
// 看第一个值
scala> arr
res10: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.head
res11: Int = 1
scala> val arr1=Array()
arr1: Array[Nothing] = Array()
scala> arr1.head
<console>:13: error: value head is not a member of Array[Nothing]
arr1.head
// 无值会出错,因此应该先判断一下
scala> val arr1:Array[Int]=Array[Int]()
arr1: Array[Int] = Array()
scala> arr1.headOption
res16: Option[Int] = None
scala> arr.headOption
res18: Option[Int] = Some(1)
scala> arr.headOption.get
res19: Int = 1
// 找数据位置
scala> arr.indexOf(3234)
res20: Int = -1
scala> arr
res21: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.indexOf(3435)
res22: Int = 2
// 序列所在位置
scala> arr
res21: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.indexOfSlice(Array(3435,22))
res24: Int = -1
scala> arr.indexOfSlice(Array(22,3435))
res25: Int = 1
// 满足条件的第一个值的下标
scala> arr
res27: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.indexWhere(x=>x%2==0)
res26: Int = 1
// 找离0.25最近的点
scala> var my=Array(0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645, 0.5742)
my: Array[Double] = Array(0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645, 0.5742)
scala> my.map(x=>(x-0.52).abs).min
res32: Double = 0.044499999999999984
scala> my(res31.indexWhere(x=>x==res32))
res34: Double = 0.5645
// 返回下标
scala> arr
res35: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.indices
res36: scala.collection.immutable.Range = Range(0, 1, 2, 3, 4, 5)
// 去掉最后一个数
scala> my
res37: Array[Double] = Array(0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645, 0.5742)
scala> my.init
res38: Array[Double] = Array(0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645)
// 每次减一个
scala> arr.inits.foreach(x=>println(x.mkString(",")))
1,22,3435,56,8,89
1,22,3435,56,8
1,22,3435,56
1,22,3435
1,22
1
// 交集
scala> arr
res47: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> val arr3=Array(1,3435,55,68,56,1232)
arr3: Array[Int] = Array(1, 3435, 55, 68, 56, 1232)
scala> arr.intersect(arr3)
res48: Array[Int] = Array(1, 3435, 56)
// 是否有该下标位置
scala> arr
res50: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.isDefinedAt(7)
res51: Boolean = false
scala> arr.isDefinedAt(6)
res52: Boolean = false
scala> arr.isDefinedAt(5)
res53: Boolean = true
// 集合是否为空
scala> arr1
res54: Array[Int] = Array()
scala> arr1.isEmpty
res55: Boolean = true
// 是否能反复遍历,iterator就不能
scala> arr1.isTraversableAgain
res57: Boolean = true
// 按照数组生成一个迭代器
scala> arr.iterator
res58: Iterator[Int] = non-empty iterator
// 取最后一个值
scala> arr.last
res60: Int = 89
// 是否有最后一个值
scala> arr.lastOption
res61: Option[Int] = Some(89)
scala> arr
res63: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
// 从右往左第一个该数
scala> arr.lastIndexOf(56)
res64: Int = 3
lastIndexWhere // 按要求从右往左搜索
// Scala中一样,再Java中size是有数据的
scala> arr.length
res65: Int = 6
scala> arr.size
res66: Int = 6
// 数组长度减去给的值,结果为差额
scala> arr
res70: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.lengthCompare(6)
res71: Int = 0
scala> arr.lengthCompare(7)
res72: Int = -1
scala> arr.lengthCompare(3)
res73: Int = 3
// 是不是不空
scala> arr
res88: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.nonEmpty
res89: Boolean = true
scala> arr1
res90: Array[Int] = Array()
scala> arr1.nonEmpty
res91: Boolean = false
// 右补齐
scala> arr
res92: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.padTo(10,0)
res93: Array[Int] = Array(1, 22, 3435, 56, 8, 89, 0, 0, 0, 0)
// 左补齐
scala> arr.reverse.padTo(10,0).reverse
res96: Array[Int] = Array(0, 0, 0, 0, 1, 22, 3435, 56, 8, 89)
scala> "hello".reverse.padTo(10,0).reverse.mkString("")
res97: String = 00000hello
// 日期补0
scala> "2017-1-15".split("-").map(x=>x.reverse.padTo(2,0).reverse.mkString("")).mkString("-")
res106: String = 2017-01-15
// 分区,只能分两个
scala> arr.partition(x=>x%2==0)
res108: (Array[Int], Array[Int]) = (Array(22, 56, 8),Array(1, 3435, 89))
// 批量替换,从第一个数字开始,往后多少个数的被替换成
scala> my
res111: Array[Double] = Array(0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645, 0.5742)
scala> arr
res112: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.patch(1,my,3)
res113: Array[AnyVal] = Array(1, 0.21169, 0.61391, 0.6341, 0.0131, 0.16541, 0.5645, 0.5742, 8, 89)
// 所有数据的各种排列组合
arr.permutations.toList.foreach(x=>println(x.mkString(",")))
// 获得满足条件的前缀长度
scala> arr
res117: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.prefixLength(x=>x<1000)
res118: Int = 2
// 乘积
scala> arr.product
res119: Int = -1281840256
// 构建左子树,且不需要初始值
scala> arr
res120: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.reduce(_+_)
res121: Int = 3611
// 构建右子树
scala> arr.reduceRight(_+_)
res122: Int = 3611
// 先做map再做reverse
scala> arr
res124: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.reverseMap(x=>x*10)
res125: Array[Int] = Array(890, 80, 560, 34350, 220, 10)
// 是否数组内容相同
scala> arr
res126: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr4
res127: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.sameElements(arr4)
res128: Boolean = true
// 顺序也得完全一样
scala> var arr5=Array(1, 22, 3435, 56, 89,8)
arr5: Array[Int] = Array(1, 22, 3435, 56, 89, 8)
scala> arr
res129: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.sameElements(arr5)
res130: Boolean = false
// 初始值一路加过去
scala> arr.scan(5)(_+_)
res136: Array[Int] = Array(5, 6, 28, 3463, 3519, 3527, 3616)
// segmentLength 从序列的 from 处开始向后查找,所有满足 p 的连续元素的长度
val a = Array(1,2,3,1,1,1,1,1,4,5)
val b = a.segmentLength( {x:Int => x < 3},3) // 5
scala> val b = a.segmentLength( {x:Int => x < 3},2)
b: Int = 0
// 0
// 切片 左包右不包
scala> arr
res139: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.slice(1,3)
res140: Array[Int] = Array(22, 3435)
// 窗口滑动
scala> arr
res142: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.sliding(3).foreach(x=>println(x.mkString(",")))
1,22,3435
22,3435,56
3435,56,8
56,8,89
// 步长为2的滑动
scala> arr.sliding(3,2).foreach(x=>println(x.mkString(",")))
1,22,3435
3435,56,8
8,89
// 排序 升序和降序,注意:降序的-号要空一格
scala> arr.sortBy(x=>x)
res0: Array[Int] = Array(1, 8, 22, 56, 89, 3435)
scala> arr.sortBy(x=> -x)
res1: Array[Int] = Array(3435, 89, 56, 22, 8, 1)
// 固定数组排序
scala> arr.sorted
res2: Array[Int] = Array(1, 8, 22, 56, 89, 3435)
// 按第一个遇到不满足条件的分割
scala> arr
res4: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.span(x=>x<1000)
res5: (Array[Int], Array[Int]) = (Array(1, 22),Array(3435, 56, 8, 89))
scala> arr.span(_<1000)
res6: (Array[Int], Array[Int]) = (Array(1, 22),Array(3435, 56, 8, 89))
// 从某个位置开始分割,分割的位置所在值在后面
scala> arr
res8: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.splitAt(3)
res9: (Array[Int], Array[Int]) = (Array(1, 22, 3435),Array(56, 8, 89))
// 是否以什么开头
scala> arr
res11: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.startsWith(Array(1,22))
res12: Boolean = true
scala> arr.startsWith(Array(22))
res13: Boolean = false
// 可从某个位置开始判定
scala> arr.startsWith(Array(22),1)
res14: Boolean = true
// 除了第一个
scala> arr
res16: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.tail
res17: Array[Int] = Array(22, 3435, 56, 8, 89)
// 拿左边几个
scala> arr.take(3)
res18: Array[Int] = Array(1, 22, 3435)
// 拿右边几个
scala> arr.takeRight(3)
res19: Array[Int] = Array(56, 8, 89)
scala> arr
res21: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
// 拿数据直到不满足
scala> arr
res21: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.takeWhile(_<100)
res22: Array[Int] = Array(1, 22)
// 类型可以不断转换
scala> arr.toList
res23: List[Int] = List(1, 22, 3435, 56, 8, 89)
scala> arr.toBuffer
res24: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 22, 3435, 56, 8, 89)
scala> arr.toBuffer.toArray
res25: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
// toMap要用数组里放元组的方式
scala> arr
res28: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.toMap
<console>:13: error: Cannot prove that Int <:< (T, U).
arr.toMap
^
scala> val arr5=Array(("name","zhangsan"),("age","20"))
arr5: Array[(String, String)] = Array((name,zhangsan), (age,20))
scala> arr5.toMap
res30: scala.collection.immutable.Map[String,String] = Map(name -> zhangsan, age -> 20)
// 矩阵转置
scala> val arr5=Array(Array("name","zhangsan"),Array("age","20"))
arr5: Array[Array[String]] = Array(Array(name, zhangsan), Array(age, 20))
scala> arr5.transpose
res34: Array[Array[String]] = Array(Array(name, age), Array(zhangsan, 20))
// union和++一样
// 2行2列转置
arr.unzip
// 3行3列转置
arr.unzip3
// 改某位的值
scala> arr
res36: Array[Int] = Array(1, 22, 3435, 56, 8, 89)
scala> arr.update(2,345)
scala> arr
res38: Array[Int] = Array(1, 22, 345, 56, 8, 89)
// 截取,左包右不包
scala> arr
res39: Array[Int] = Array(1, 22, 345, 56, 8, 89)
scala> arr.view(1,4).toList
res40: List[Int] = List(22, 345, 56)
// 对应位置按对拿出,按短的算
scala> arr
res42: Array[Int] = Array(1, 22, 345, 56, 8, 89)
scala> val arr2=Array(33,345,5656)
arr2: Array[Int] = Array(33, 345, 5656)
scala> arr.zip(arr2)
res43: Array[(Int, Int)] = Array((1,33), (22,345), (345,5656))

2.元组
特点
可以包含不同类型的元素
最多支持22个元素
使用下划线
_访问元素,_1是第一个元素元组中值不可更改
1
2
3
4
5
6
7
8
9
10scala> val tup=(1,"zs",20,175.2,"1999-10-12")
tup: (Int, String, Int, Double, String) = (1,zs,20,175.2,1999-10-12)
scala> tup._1
res44: Int = 1
scala> tup._1=2
<console>:12: error: reassignment to val
tup._1=2
^主要就用
productIterator变成迭代器来使用奇怪语法
一次性定义很多变量
1
2
3
4
5
6
7
8scala> val tup=(1,"zs",20,175.2,"1999-10-12")
tup: (Int, String, Int, Double, String) = (1,zs,20,175.2,1999-10-12)
scala> val (stuid,stuname,stuage,high,birthday)=tup
stuid: Int = 1
stuname: String = zs
stuage: Int = 20
high: Double = 175.2
birthday: String = 1999-10-12
3.集合
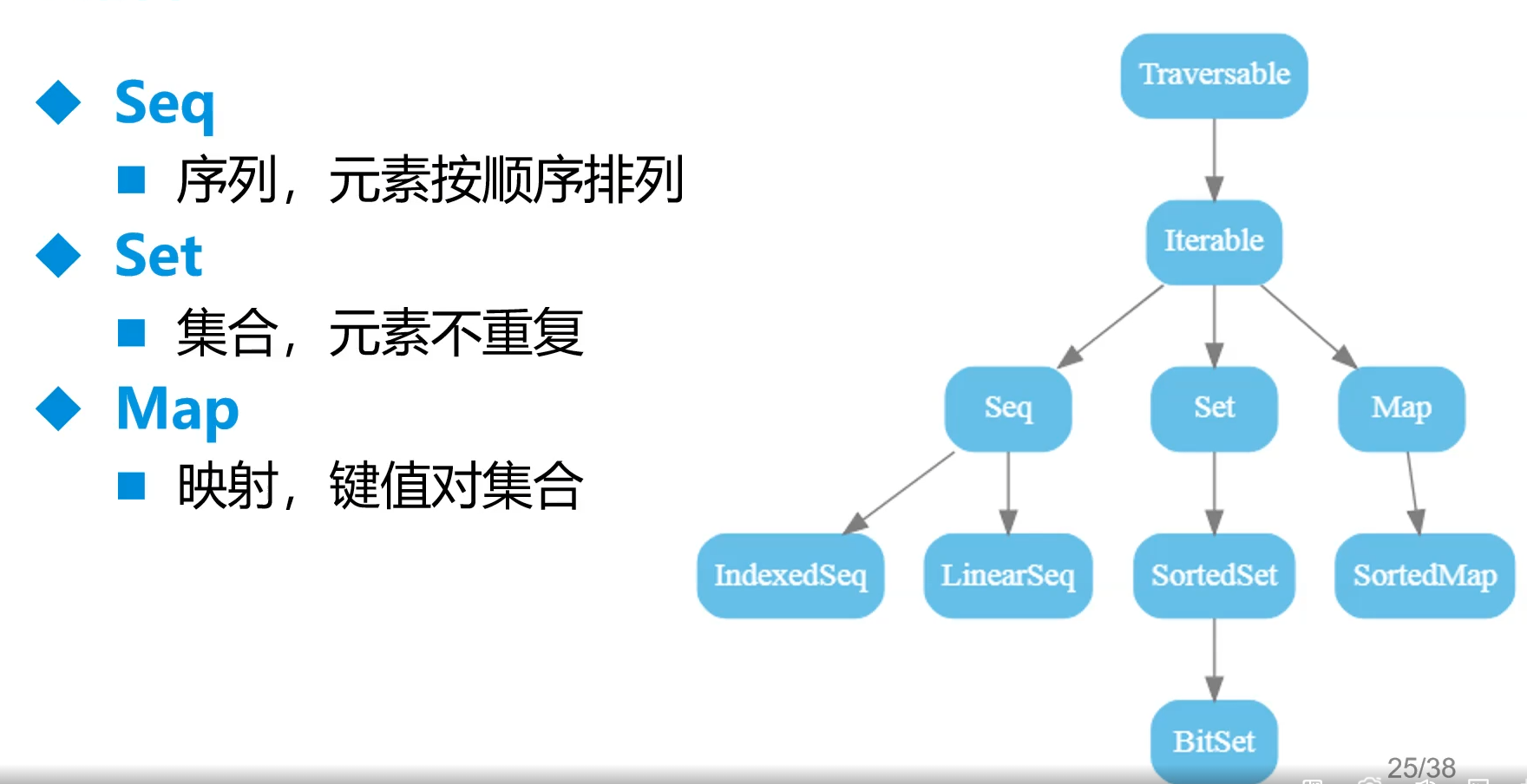
A.前期
Traversable是顶级集合类
集合类别
不可变集合
scala.collection.immutable,默认Scala选择不可变集合例子
1
2
3
4
5
6
7
8
9
10scala> val aa=List(1,2,3)
aa: List[Int] = List(1, 2, 3)
scala> aa.getClass
res47: Class[_ <: List[Int]] = class scala.collection.immutable.$colon$colon
scala> aa(1)=111
<console>:13: error: value update is not a member of List[Int]
aa(1)=111
^上面全是类 常用Set Seq Map HashMap
可变集合:可以修改、添加或移除一个集合的元素
scala.colection.mutable方法里带
=的例子
1
2
3
4
5
6
7
8scala> val lb = scala.collection.mutable.ListBuffer(1,2,3)
lb: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3)
scala> lb += 22
res49: lb.type = ListBuffer(1, 2, 3, 22)
scala> lb.+=(22)
res50: lb.type = ListBuffer(1, 2, 3, 22, 22)-
常用Map Seq Set ArrayBuffer ListBuffer HashMap StringBuffer
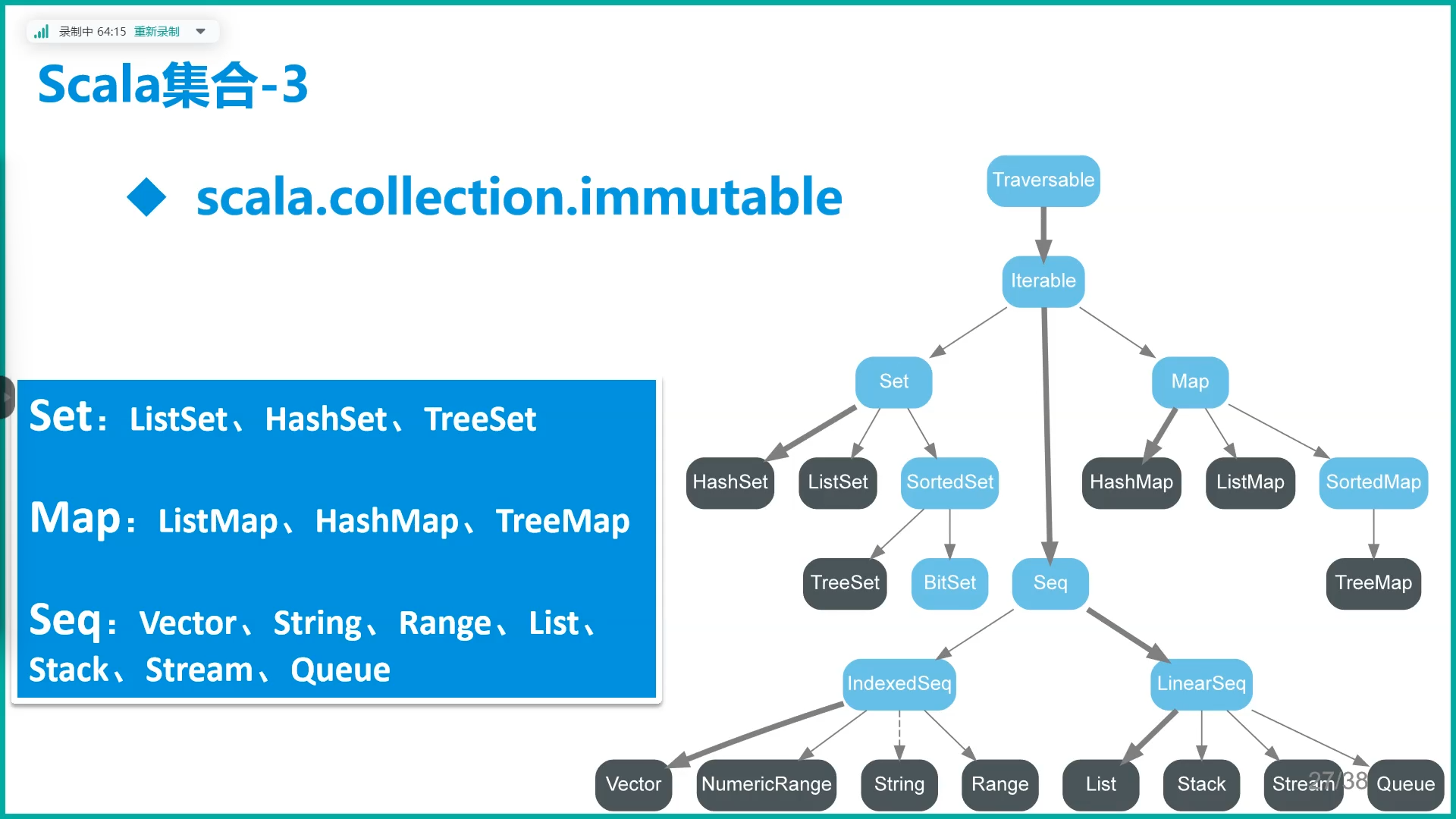
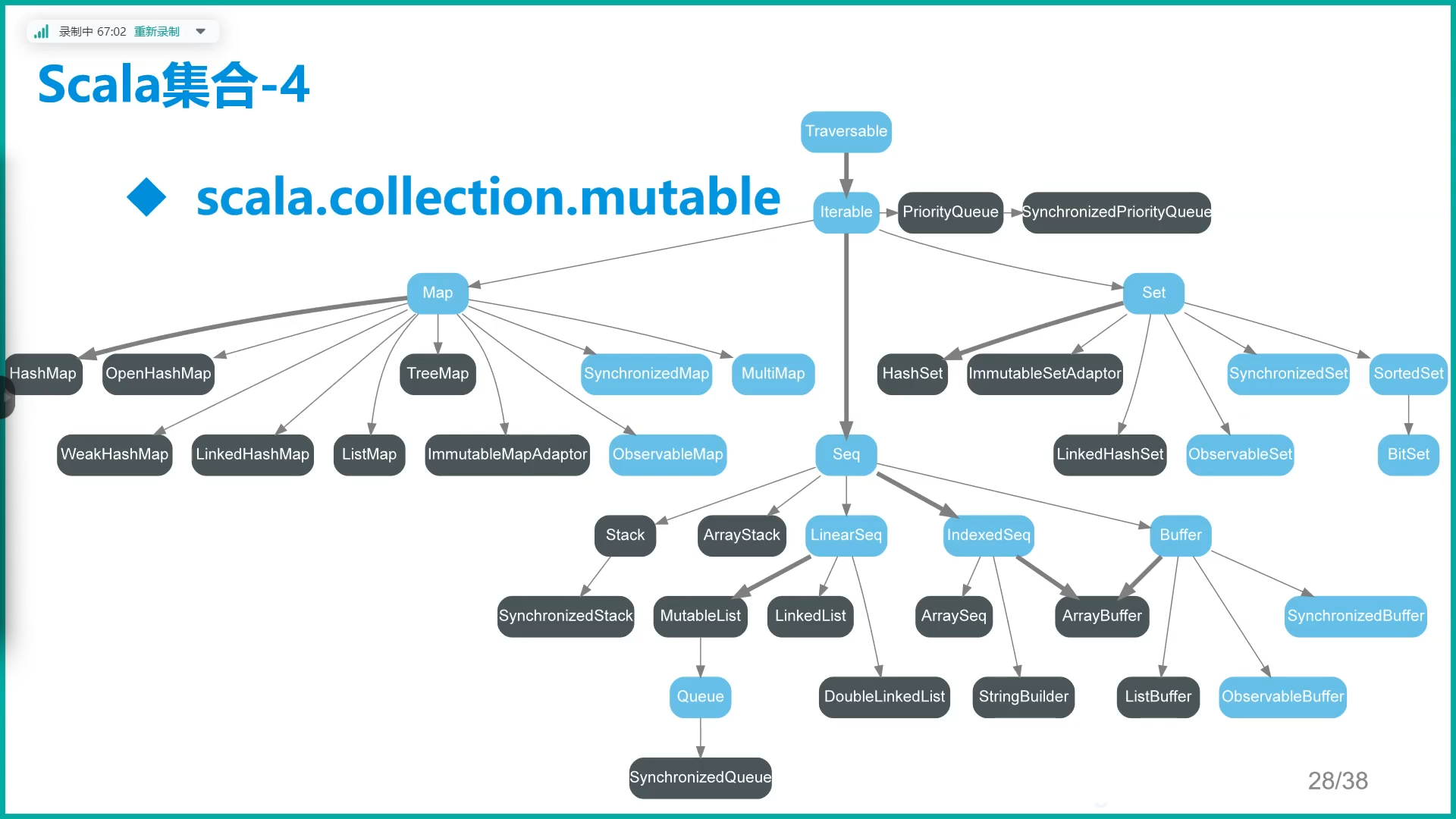
B.常用集合

C.Map

- 拿值要m(key) 或者 m.get(key).get
(六)练习
工程文件为
scala/myexp原始数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// student
01,赵雷,1990-01-01,男
02,钱电,1990-12-21,男
03,孙风,1990-05-20,男
04,李云,1990-08-06,男
05,周梅,1991-12-01,女
06,吴兰,1992-03-01,女
07,郑竹,1989-07-01,女
08,王菊,1990-01-20,女
// sc
01,01,80
01,02,90
01,03,99
02,01,70
02,02,60
02,03,80
03,01,80
03,02,80
03,03,80
04,01,50
04,02,30
04,03,20
05,01,76
05,02,87
06,01,31
06,03,34
07,02,89
07,03,98
// Course
01,语文,02
02,数学,01
03,英语,03
// teacherp
01,张三
02,李四
03,王五1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43// 读数据,用专门的函数,以及实体类来存储
// 四个实体类
case class Course(cid:String,cname:String,tid:String)
case class Score(sid:String,cid:String,score:Int)
case class Student(sid:String,name:String,birthday:String,gender:String)
case class Teacher(tid:String,tname:String)
// 枚举类
object TableEnum extends Enumeration {
type TableEnum = Value
val SCORE,STUDENT,TEACHER,COURSE=Value
}
// 主类中,相关函数和使用
object Exp1To5 {
def readTxtToBuffer(path: String,model:TableEnum): ListBuffer[Any] = {
val reader = new BufferedReader(new FileReader(path));
var scData = ListBuffer[Any]();
var line: String = reader.readLine();
while (line != null) {
val infos = line.split(",")
model match{
case SCORE=> scData+=Score(infos(0),infos(1),infos(2).toInt)
case TEACHER=> scData+=Teacher(infos(0),infos(1))
case STUDENT => scData+=Student(infos(0),infos(1),infos(2),infos(3))
case COURSE => scData+=Course(infos(0),infos(1),infos(2))
}
line = reader.readLine();
}
reader.close();
scData
}
def main(args: Array[String]): Unit = {
val lb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\sc.txt",SCORE);
lb.map(x => {
val tuple = x.asInstanceOf[Score]
tuple
}).foreach(x=>println(x))
}
}
第1题
查询”01”课程比”02”课程成绩高的学生的信息及课程分数
法1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 1. 先查出所有01课程的学员及分数
val oneSc = scData.filter(x=>x._2.equals("01"));
val twoSc = scData.filter(x=>x._2.equals("02"));
println(oneSc)
println(twoSc)
// 2.使用偏函数遍历01课程集合 再02课程中进行搜索
var bb=oneSc.flatMap(tup=>{
twoSc.map(tup02=> {
if (tup._1.equals(tup02._1)) {
Array(tup._1,tup._3,tup02._3)
} else{
Array()
}
})
}).filter(x=>x.size!=0 && x(1).toString.toInt > x(2).toString.toInt).map(x=>(x(0),x(1),x(2)))
println(bb)法2
1
2
3
4
5val bb = scData.filter(x => x._2.equals("01") || x._2.equals("02"))
.groupBy(x => x._1).map(x=>x._2.sortBy(e=>e._2))
.filter(p=>p.size==2 && p(0)._3>p(1)._3)
println(bb)
第3题
- 第3题:查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
1 | val scorelb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\sc.txt",SCORE) |
第5题
第5题:查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18val scorelb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\sc.txt",SCORE)
.map(_.asInstanceOf[Score]);
val stulb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\student.txt",STUDENT)
.map(s=>{
val stu = s.asInstanceOf[Student];
(stu.sid,stu)
}).toMap
val res = scorelb.groupBy(_.sid).map(lb=>{
var cnt_score = 0;
lb._2.foreach(s=>cnt_score+=s.score)
(lb._1,(lb._2.size,cnt_score))
})
val res1 = stulb.map(x => {
val findScore = res.getOrElse(x._1, (0, 0));
(x._1,x._2.name, findScore._1,findScore._2)
})
println(res1)要进行一个外联,因为可能有人没有考,用
getOrElse方式取值
第7题
第7题:查询学过”张三”老师授课的同学的信息
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 第7题:查询学过"张三"老师授课的同学的信息
val scorelb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\sc.txt",SCORE)
.map(_.asInstanceOf[Score]);
val stulb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\student.txt",STUDENT)
.map(s=>{
val stu = s.asInstanceOf[Student];
(stu.sid,stu)
}).toMap
val tealb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\teacher.txt",TEACHER)
.map(_.asInstanceOf[Teacher]);
val courselb = readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\course.txt",COURSE)
.map(_.asInstanceOf[Course]);
val teacher = tealb.filter(x => x.tname.equals("张三"))(0)
val courses = courselb.filter(x => x.tid.equals(teacher.tid))
.map(x=>(x.cid,x.cname)).toMap
println(courses)
val scc = scorelb.collect({
case x if (courses.get(x.cid) != None) => x.sid
}).distinct.map(stuid=>stulb.get(stuid).get)
println(scc)
其他
(七)其他语法
map(_.asInstanceOf[类型])强转,对集合中每个值墙砖类型Any相当于Java中的Object
二元组和Map可以相互转化
如果lambda只有一条语句,省略
{},可从x=>{x<100}变为x=>x<100如果参数只用一次可从
x=>x<100变为_<100每个单词开头大写
1
2
3
4
5
6
7
8
9
10def toTitle(str:String): String ={
val pattern = "([a-zA-Z']*[^a-z|A-Z|']+)|[a-zA-Z']+".r;
val li = pattern.findAllIn(str)
.map(x=>x(0).toUpper+x.toLowerCase.substring(1)).mkString;
li;
}
def main(args: Array[String]): Unit = {
println(toTitle("what do you want to do?let's go"))
}
// 出What Do You Want To Do?Let's Go
(八)面向对象编程

1.类
- 初步
- 类通过class关键字定义
- 类通过new关键字创建实例
- 类拥有成员变量和方法
- 类的成员默认为public,也支持private、protected
- 类中无法定义静态成员变量和方法
- 类无需明确定义构造方法,通过构造参数列表声明为类的一部分
A.类访问修饰符
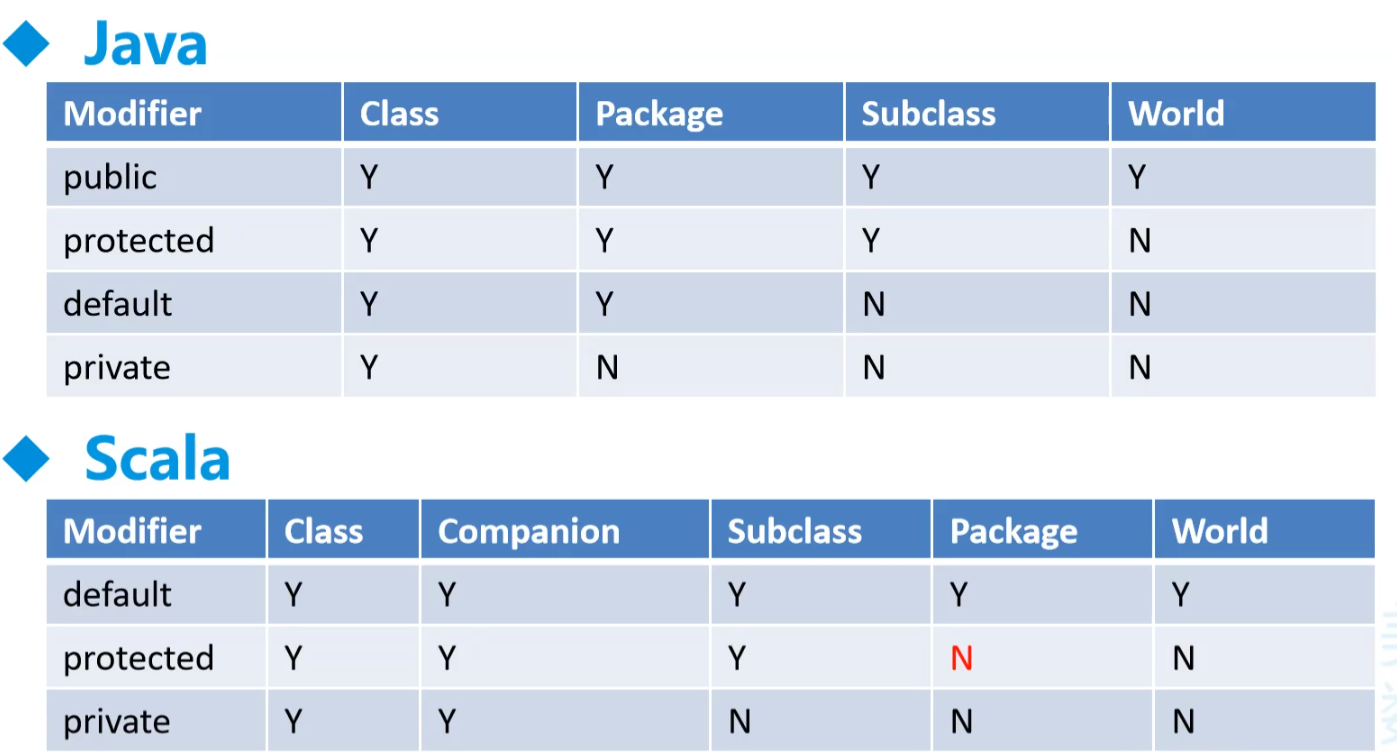
B.类的定义
主构造器,辅助构造器
参数构造直接在后面用括号
class中不允许有静态方法,要在object中new
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class FirstClazz(name:String,age:Int){
val username=name;
val userage=age;
def this()={
this("zs",20)
}
def add(num1:Int,num2:Int)={
s"${num1}+${num2}=${num1+num2},${username},${userage}"
}
}
object MyMain {
def main(args: Array[String]): Unit = {
val fc = new FirstClazz()
println(fc.add(10, 34))
}
}
// 10+34=44,zs,20

2.抽象类

3.单例对象
- Scala的类中无法定义静态成员,像Java一样表达类的静态成员变量、成员方法与静态代码块?
- Scala解决方案:单例对象
- 使用“object”关键字声明,可包含变量、方法与代码定义
- 单例对象中的成员变量、成员方法通过单例对象名直接调用
- 单例对象第一次被访问时初始化,并执行全部代码块
- 单例对象不能new,且无构造参数
- 程序入口main()方法必须定义在单例对象中
- 单例对象与同名类定义在同一文件中时形成绑定关系
A.伴生对象
伴生类和伴生对象,名字要相同,要在同一个文件中
apply是直接弹出来的
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import com.njupt.myexp.MyClassObject.uname
// 伴生类
class MyClassObject(name:String) {
val username=name;
def printName()={
print(s"Hello,${username},${uname}")
}
}
// 伴生对象
object MyClassObject{
def uname="ls"
def apply(name: String): MyClassObject = new MyClassObject(name)
def unapply(arg: MyClassObject): Option[String] = Some(uname) // 只能拿到这边对象的
}
// 在其他文件中 两种方法都可以使用
// val za = new MyClassObject("za")
val za = MyClassObject("za")
za.printName()
// 输出Hello,za,ls解释
类可以输出对象中的方法
方法不能直接调用类中的东西
上面那个uname
apply是相当于在外部不要new
unapply相当于是toString
4.隐式类
可以增强功能,但是不用改原本的类
可以看到ImClazz原本没有xxx()但是可用,在上面隐式类中参数要是相应类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class ImClazz {
def sayHello()={
println("Hello")
}
}
object MyMain {
implicit class AddFunc(xx:ImClazz) {
def xxx():Unit={
println("xxx")
}
}
def main(args: Array[String]): Unit = {
val ic = new ImClazz();
ic.sayHello();
ic.xxx();
}
}
5.特质trait
A.概述与概念
- Scala中没有接口(interface)的概念
- 特质用于在类之间共享程序接口和字段,类似Java接口
- 特质是字段和方法的集合,可以提供字段和方法实现
- 类和单例对象都可以扩展特质(extends)
- 特质不能被实例化,因此没有构造参数,类似Java接口
- 特质使用”trait”关键字定义
- 实现特质中的方法使用”override”
- 可实现动态混入特质
B.混入特质

类能继承它,它也能继承普通类
C.动态混入特质
类似于接口
动态混入,一个类中只能一个,而且,但是可以让多个trait互相继承,一次性导入
代码样例,重写前面练习中的读入文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43trait DataChangeTrait [T]{
def change(line:String):T
}
trait ScoreChangeTrait extends DataChangeTrait[Score]{
override def change(line: String): Score = {
val infos = line.split(",")
Score(infos(0),infos(1),infos(2).toInt)
}
}
trait StudentChangeTrait extends DataChangeTrait[Student]{
override def change(line: String): Student = {
val infos = line.split(",")
Student(infos(0),infos(1),infos(2),infos(3))
}
}
class DataChangeTool[T] {
self:DataChangeTrait[T] =>
def readTxtToBuffer(path: String): ListBuffer[T] = {
val reader = new BufferedReader(new FileReader(path));
val scData = ListBuffer[T]();
var line: String = reader.readLine();
while (line != null) {
scData += change(line);
line = reader.readLine();
}
reader.close();
scData
}
}
object MyTest {
def main(args: Array[String]): Unit = {
val scores = (new DataChangeTool[Score]() with ScoreChangeTrait).readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\sc.txt")
println(scores)
val stus = (new DataChangeTool[Student]() with StudentChangeTrait).readTxtToBuffer("E:\\ProgramFile\\BigDataStudy\\data\\scalaexp\\student.txt")
println(stus)
}
}
// 数据到这儿把两个文件的读出,后续只要多加一个特质,继承需要混入的特质

6.样例类

- 相当于实体类,但是出来默认是val,是不可变的
7.枚举类
要继承
Enumerationobject TableEnum extends Enumeration { type TableEnum = Value // 把枚举类暴露出去 val SCORE,STUDENT,TEACHER,COURSE=Value }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
### 8.泛型类

- 例子
压栈,输出新的List
```scala
scala> val lst=List[Int]()
lst: List[Int] = List()
scala> 10 :: lst
res0: List[Int] = List(10)
scala> 20 :: (10 :: lst)
res1: List[Int] = List(20, 10)
9.类型边界
- 在Scala中,类型参数可以有一个类型边界约束
- 类型上界:将类型限制为另一种类型的子类
- T<:A 表示类型变量T应该是类型A的子类
- A是具体类型,T是泛型
- 类型下界:将类型声明为另一种类型的超类
- T>:A 表示类型变量T应该是类型A的超类
- A是具体类型,T是泛型
(九)进阶学习
1.Scala正则表达
- 分割 匹配 替换 提取
A.初步
一旦使用
\就用"""regex""".r例1 match提取方式
1
2
3
4
5
6val str = "1234566 1999-10-12T12:34:56 buy http://www.taobao.com/computer/1"
val pattern = "([0-9]+) ([0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}) ([a-z]+) .*".r
str match {
case pattern(userid,times,action)=>println(s"${userid},${times},${action}")
}
// 1234566,1999-10-12T12:34:56,buy

B.字符串匹配
-
例1
1
2
3
4
5val str = "1234566 1999-10-12T12:34:56 buy http://www.taobao.com/computer/1 1999-10-12T12:34:56"
val pattern = "[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}".r
val matches = pattern.findAllMatchIn(str).toList
println(matches)
// List(1999-10-12T12:34:56, 1999-10-12T12:34:56)findFirstMatchIn() 出Some和None
findAllMatchIn() 出Iterator
例2 利用偏心函数对每一条获取值并输出
1
2
3
4
5
6
7
8
9
10val lst = List[String](
"INFO 2017-12-29 requestURL:/c?abc=123&cde=456",
"INFO 2017-12-30 requestURL:/c?abc=123&cde=789",
"INFO 2017-12-30 requestURL:/c?abc=123&cde=346"
)
val pattern = """([A-Z]+) ([0-9]{4}-[0-9]{2}-[0-9]{2}) requestURL:(/.*)""".r
lst.collect({
case pattern(level,times,addr)=>(level,times,addr)
}).foreach(println)

C.字符串替换

2.
最后
- 标题: 大数据学习笔记3-Scala
- 作者: Sabthever
- 创建于 : 2025-05-27 19:08:34
- 更新于 : 2025-10-09 16:14:31
- 链接: https://sabthever.cn/2025/05/27/technology/bigdata/Hadoop3-Scala/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
